목차
검색 엔진과 그래프
페이지랭크 알고리즘
배경
- 웹
- 웹은 웹페이지와 하이퍼링크로 구성된 거대한 방향성이 있는 그래프
- 웹페이지는 정점
- 하이퍼링크는 나가는 간선
- 웹페이지는 키워드 정보를 포함
- 초창기에는 (야후) 웹을 거대한 디렉토리로 정리했음
- 카테고리의 수와 깊이가 무한으로 커짐
- 두번째는 웹페이지에 포함된 키워드에 의존한 검색 엔진
- 광고 사이트 등으로 들어갈 수 있음
- 키워드와 관련성이 높고 신뢰할 수 있는 웹페이지를 어떻게 찾을 수 있을까?
- 구글 창업자 래리 페이지와 세르게이 브린의 페이지랭크 논문이 답을 줌
정의
- 핵심 아이디어 : 투표, 투표를 통해 사용자 키워드와 관련성 높고 신뢰할 수 있는 웹페이지 찾음
- 투표의 주체는 웹페이지, 웹페이지는 하이퍼링크를 통해 투표함
- 웹페이지 u 가 웹페이지 v 로의 하이퍼링크를 포함하면, u 가 v 에게 투표한 것 (u 의 작성자가 v 를 키워드와 관계 있고 신뢰)
- 들어오는 간선이 많을 수록 신뢰할 수 있는 웹페이지
- 들어오는 간선의 수를 세는 것으로 충분할까?
- NO. 웹페이지를 여러 개 만들어서 간선의 수를 부풀릴 수 있음.
- 돈을 주고 트위터 팔로워를 높일 수도 있음.
- 악용을 막기 위해 페이지랭크는 가중 투표를 함
- 관련성이 높고 신뢰할 수 있는 웹사이트의 투표를 더 중요하게 간주
- 관련성과 신뢰성을 어떻게 알까?
- 재귀, 연립방정식 풀이로 파악
- 들어오는 간선의 수를 세는 것으로 충분할까?
- 측정하려는 웹페이지의 관련성 및 신뢰도를 페이지랭크 점수라 함
- 각 웹페이지는 나가는 이웃에게 자신의 (페이지랭크 점수 / 나가는 이웃의 수) 만큼의 가중치로 투표를 함

- 페이지랭크는 임의 보행 (Random Walk) 관점으로도 설명 가능
- 임의 보행을 통해 웹을 서핑하는 웹서퍼를 가정
- 웹서퍼는 현재 웹페이지의 하이퍼링크 중 하나를 균일한 확률로 클릭
- 웹서퍼가 t 번째 방문한 웹페이지가 웹페이지 i 일 확률은 $p_i(t)$.
- p(t) 는 길이가 웹페이지 수와 같은 확률분포 벡터가 됨
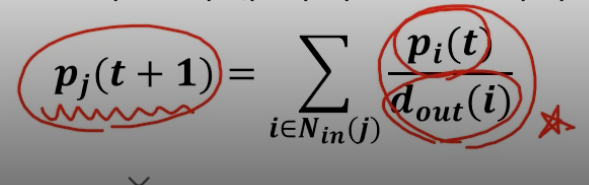
- 위 과정을 무한히 반복, t 가 무한히 커지면 확률 분포 p(t) 는 수렴
- 다시 말해 p(t) = p(t+1) = p.
- 수렴한 확률 분포 p 는 정상 분포 (Stationary Distribution)
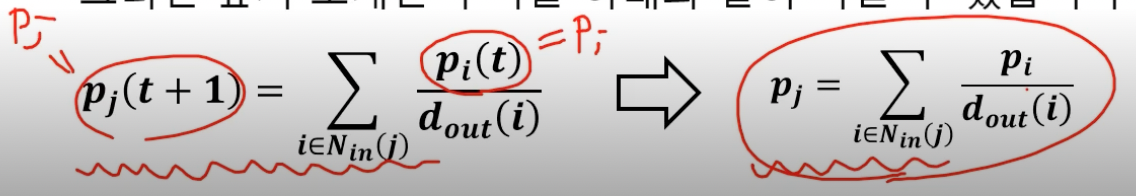
- 앞서 본 투표 관점의 페이지랭크 수식과 비슷

페이지랭크 계산
- 반복곱 (Power Iteration) 사용
- 1) 각 웹페이지 i 의 페이지랭크 점수 $r_i(0)$ 를 동일하게 1 / 웹페이지 수 로 초기화
- 2) 페이지랭크 식을 이용하여 각 웹페이지의 페이지랭크 점수 갱신
- 3) 페이지랭크 점수가 수렴하면 종료. 아니면 2) 반복.
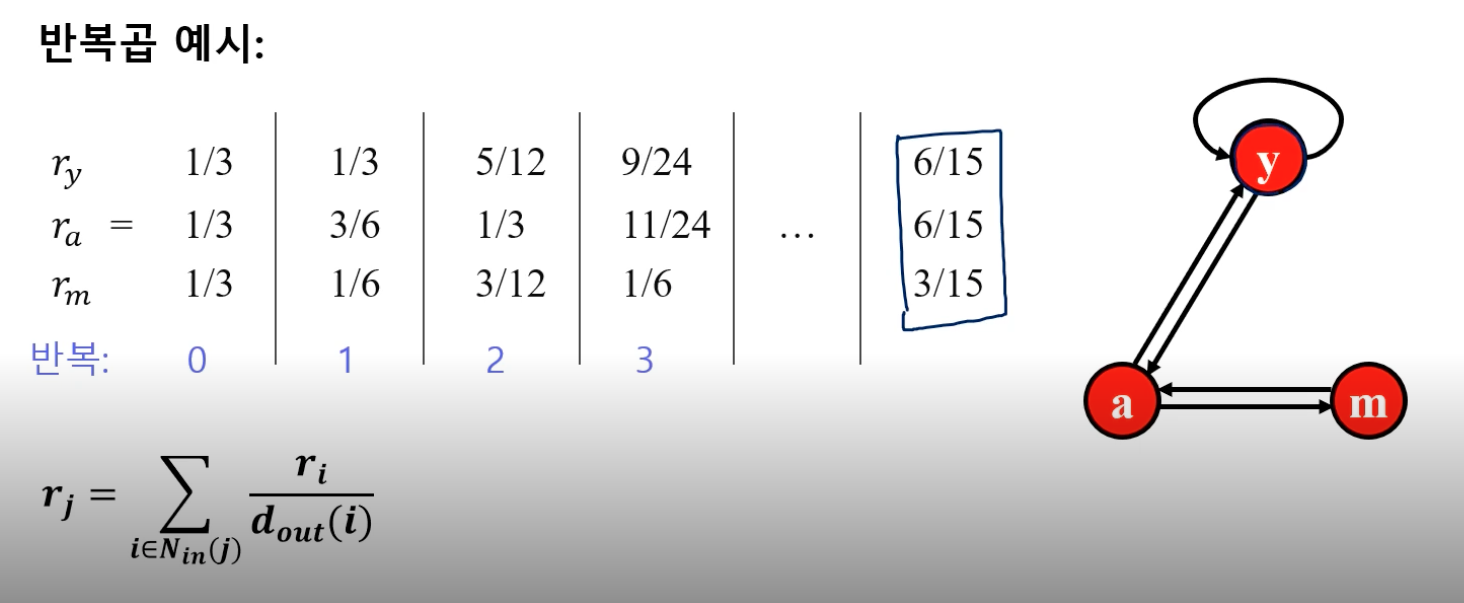
-
반복곱이 항상 수렴할까?

- No. 스파이더 트랩 때문.
- 위 사진은 2 칸 간격으로 같음.
-
반복곱이 합리적인 점수로 수렴할까?

- No. 막다른 정점 때문
- 0 으로 수렴.
- 위 문제를 해결하기 위해 순간이동 (Teleport) 도입
- 1) 현재 웹페이지에 하이퍼링크가 없다면, 임의의 웹페이지로 순간이동
- 2) 있다면, 앞면이 나올 확률이 a 인 동전을 던짐
- 3) 앞면이면, 하이퍼링크 중 하나를 균일한 확률로 선택
- 4) 뒷면이면, 임의의 웹페이지로 순간이동
- 임의의 웹페이지로 이동함으로써 스파이더 트랩이나 막다른 정점에 갇히지 않음
- a 는 감폭 비율 (Damping Factor) 라고 부르며 보통 0.8 사용
- 순간이동을 적용한 페이지랭크 점수 계산
- 1) 각 막다른 정점에서 (자신을 포함) 모든 다른 정점으로 가는 간선 추가
- 2) 아래 수식을 사용하여 반복곱 수행

Further Reading
- http://infolab.stanford.edu/~ullman/mmds/ch5.pdf
- http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
바이럴 마케팅과 그래프
그래프를 통한 정보의 전파
- SNS 를 통해 다양한 정보가 전파됨
- 스페인 시위 등
- SNS 를 통해 다양한 행동도 전파됨
- 아이스 버킷 챌린지 등
- 컴퓨터 네트워크에서는 일부 장비의 고장이 전파되어 전체 네트워크를 마비시킬 수 있음
- 파워 그리드에서 정전이 전파되는 것도 유사
- 사회라는 거대한 소셜 네트워크에서 질병의 전파도 있음
- 코로나19
- 전파 과정은 다양하고 매우 복잡하므로 체계적으로 대처하기 위해 수학적 모형화가 필요
의사결정 기반의 전파 모형
- 카카오톡과 라인 중에 어떤 것을 사용할까?
- 주변 사람들의 의사결정이 본인의 의사결정에 영향을 미침
- 친구들이 카톡을 쓰기 때문에 카톡 사용
- 주변 사람들의 의사결정을 고려한 의사결정을 내리는 경우, 의사결정 기반의 전파 모형 사용
- 가장 간단한 모형인 선형 임계치 모형 (Linear Threshold Model) 소개
선형 임계치 모형
- 친구 u 와 v 가 두 개의 호환되지 않는 기술 A 와 B 중에서 하나를 선택
- 둘 모두 A 를 사용하면 행복이 a 만큼 증가
- 둘 모두 B 를 사용하면 행복이 b 만큼 증가
- 하지만 서로 다른 기술을 사용하면 행복 증가 x
- 같은 기술을 사용하면 서로 주고 받을 수 있기 때문에 행복 증가
- 소셜 네트워크 예시. A 기술 사용 친구 2명, B 기술 사용 친구 3명.
- 각자가 행복이 최대화되는 선택을 한다고 가정
- 2a > 3b 면 A 선택
- 2a < 3b 면 B 선택
- 2a == 3b 면 B 선택
- 일반화. p 비율 A 선택, 1-p 비율 B 선택
-
A 를 선택하는 경우, ap > b(a-p)
→ p > (b/a+b) 일 때 A 선택.
- (b/a+b) 를 임계치 q 라고 함.
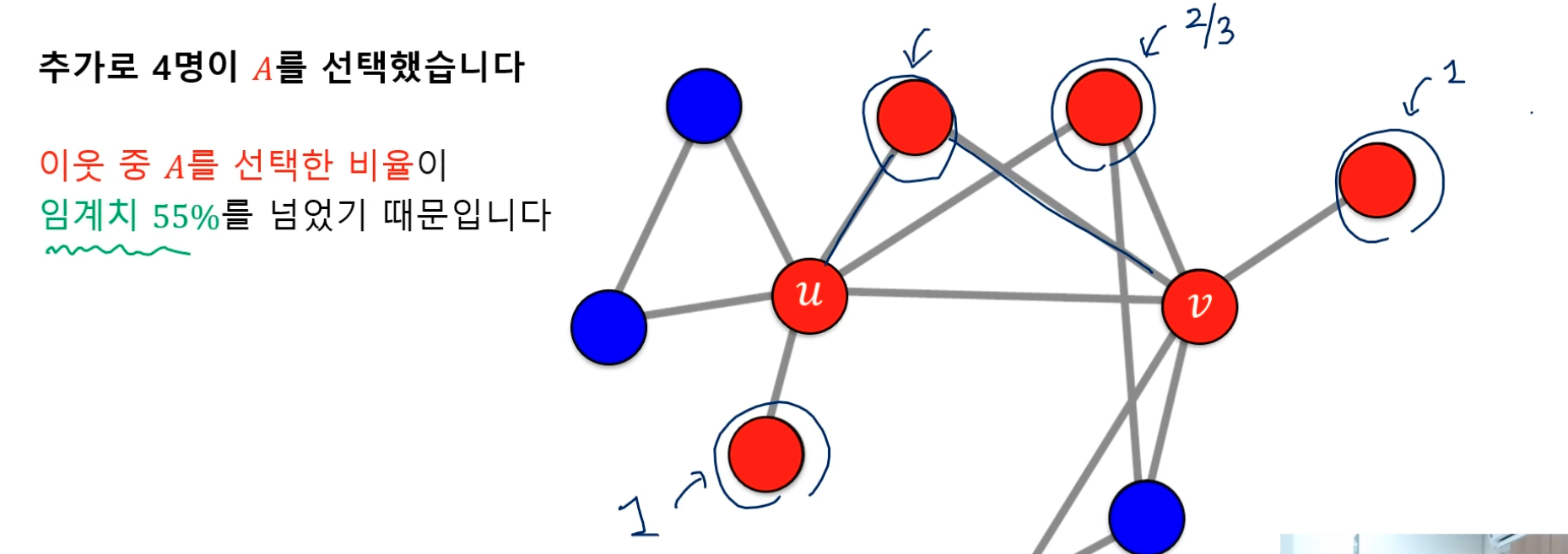
- 선형 임계치 모형, 각 정점은 이웃 중 A 를 선택한 비율이 임계치 q 를 넘을 때만 A 를 선택.
- 이 모형은 모두 B 를 사용하는 상황 가정 (기존)
- 처음 A 를 사용하는 얼리 어답터 가정 (신규 기술)
- 시드 집합 (Seed Set) 이라고 불리는 얼리 어답터들은 항상 A 를 고수함
- 예시
- 임계치 q = 0.55
- u 와 v 는 시드 집합. (u 와 v, 얼리 어답터의 등장으로 주변에 영향을 줌)
확률적 전파 모형
- 코로나의 전파는 의사 결정 전파 모형이 맞지 않음 (걸리는 걸 의사 결정하지 않기 때문)
- 코로나의 전파는 확률적 과정이므로 확률적 전파 모형을 고려해야함
- 가장 간단한 형태의 확률적 전파 모형인 독립 전파 모형 (Independent Cascade Model) 소개
독립적 전파 모형
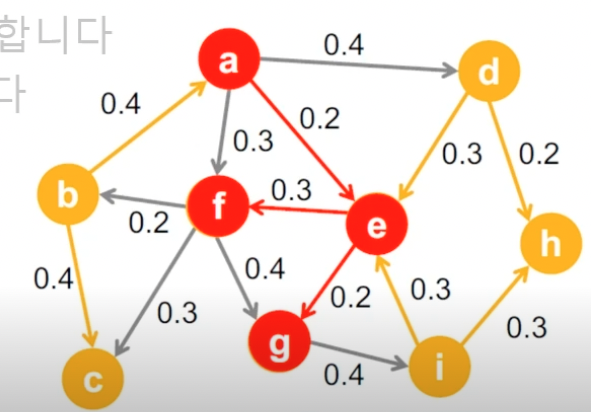
- 방향성이 있고 가중치가 있는 그래프 가정
- 각 간선 (u, v) 의 가중치 $p_\mathit{uv}$ 는 u 가 감염되었을 때 (v 는 감염 안됨) u 가 v 를 감염시킬 확률.
- 각 정점 u 가 감염될 때마다, 각 이웃 v 는 $p_\mathit{uv}$ 확률로 전염됨
- 서로 다른 이웃이 전염되는 확률은 독립적. u 가 v 를 감염시킬 확률과 u 가 w 를 감염시킬 확률은 독립적.
- 모형은 최초 감염자 시드 집합으로부터 시작
- 더 이상 새로운 감염자가 없으면 종료
- 감염자는 계속 감염자 상태로 남아있는 것을 가정, 감염자의 회복을 가정하는 SIS, SIR 등의 다른 전파 모형도 있음
바이럴 마케팅과 전파 최대화 문제
바이럴 마케팅
- 소비자로 하여금 상품에 대한 긍정적인 입소문을 내게 하는 기법
- 효과적으로 하기 위해서는 소문의 시작점이 중요, 입소문이 전파되는 범위가 영향받기 때문 (소셜 인플루언서가 높은 광고비를 받는 이유)
시드 집합의 중요성
- 앞서 본 전파 모형들에서도 시드 집합이 전파 크기에 많은 영향을 미쳤음
- 그래프, 전파 모형, 시드 집합의 크기가 주어졌을 때 전파를 최대화하는 시드 집합을 찾는 문제를 전파 최대화 (Influence Maximization) 문제라고 함
- 전파 최대화 문제는 매우 어려움. 그래프에 |V| 개의 정점이 있을 경우, 시드 집합의 크기를 k 개로 제한하여도 경우의 수는 VCk, 매우 많음
-
이론적으로 많은 전파 모형에 대해 전파 최대화 문제는 NP-hard 임이 증명됨
→ 최고의 시드 집합 찾기 포기
정점 중심성 휴리스틱 (근사 알고리즘 사용)
- 대표적 휴리스틱으로 정점의 중심성 (Node Centrality) 사용
- 시드 집합 크기가 k 개로 고정되어 있을 때, 정점의 중심성이 높은 순으로 k 개 정점 선택
- 정점의 중심성으로는 페이지랭크 점수, 연결 중심성, 근접 중심성, 매개 중심성 등이 있음
- 합리적인 방법이지만, 최고의 시드 집합을 찾는다는 보장이 없음
탐욕 알고리즘 (Greedy Algorithm)
- 전파 최대화 문제를 풀기 위해 그리디 알고리즘 역시 많이 사용됨
- 시드 집합의 원소, 즉 최초 전파자를 한 번에 한 명씩 선택.
- 한 명의 최초 전파자를 찾기 위해 크기가 1 인 부분집합의 값을 비교하여 전파를 최대화하는 시드 집합 {x} 집합 찾음.
- x 를 기반으로 다음 전파자 찾음. 크기 2 인 부분집합 비교. 전파를 최대화하는 시드 집합 {x, y} 찾음.
- 위 과정을 목표하는 크기의 시드 집합에 도달할 때까지 반복
- 최초 전파자 간의 조합의 효과를 고려하지 않고 근시안적으로 최초 전파자를 선택
-
독립 전파 모형에 적용할 경우, 이론적으로 정확도가 일부 보장됨 (최저 성능 보장). 항상 입력 그래프와 무관하게 다음 부등식 성립

Further Questions
- 감염병의 전파를 모델링 하기 위해서는 감염과 더불어 감염된 환자의 회복을 고려해야 합니다. 감염된 사람이 회복될 수 있고, 한 번 감염이 된 사람은 추가적으로 감염이 되지 않는다고 가정한다면 어떻게 전파 모델을 설계할 수 있을까요?
-> SIR 모델로 설계하여 회복된 사람의 노드는 R 상태로 둔다.
Futher Reading
피어 세션
수업 질문
[펭귄] 페이지랭크 알고리즘에서 1-α가 의사코드에서는 1-S로 대체되는 이유
Today I Felt
P Stage 주제 고민
오늘 P Stage 의 주제들이 나왔다. 총 4 단계 (+ 스페셜 스테이지) 의 스테이지로 구성되어 있으며 각 단계마다 여러 태스크가 있어서 그 중 하나를 선택하면 된다. 스테이지 1 은 공통으로 이미지 분류 태스크를 수행한다. 스테이지 2~4 는 선택인데 나는 자연어 처리 서비스를 다뤄보고 싶기 때문에 ‘한국어 언어 모델 학습 및 다중 과제 튜닝’, ‘기계 독해’, ‘Deep Knowledge Tracking’ 을 선택할 예정이다. 그리고 스페셜 스테이지로 데이터 시각화도 참가할 것이다. 과정이 끝나고 나는 자연어 처리에 대한 깊은 이해를 바탕으로 시퀀스 데이터와 관련된 문제 처리 전문가가 되고 싶다.