목차
- Sequence to Sequence with Attention
- Beam Search and BLEU
- Seq2Seq 구현
- Seq2Seq with Attention 구현
- Seq2Seq Model Training with Fairseq
- 마스터 클래스
- 피어 세션
- Today I Felt
Sequence to Sequence with Attention
Seq2Seq Model
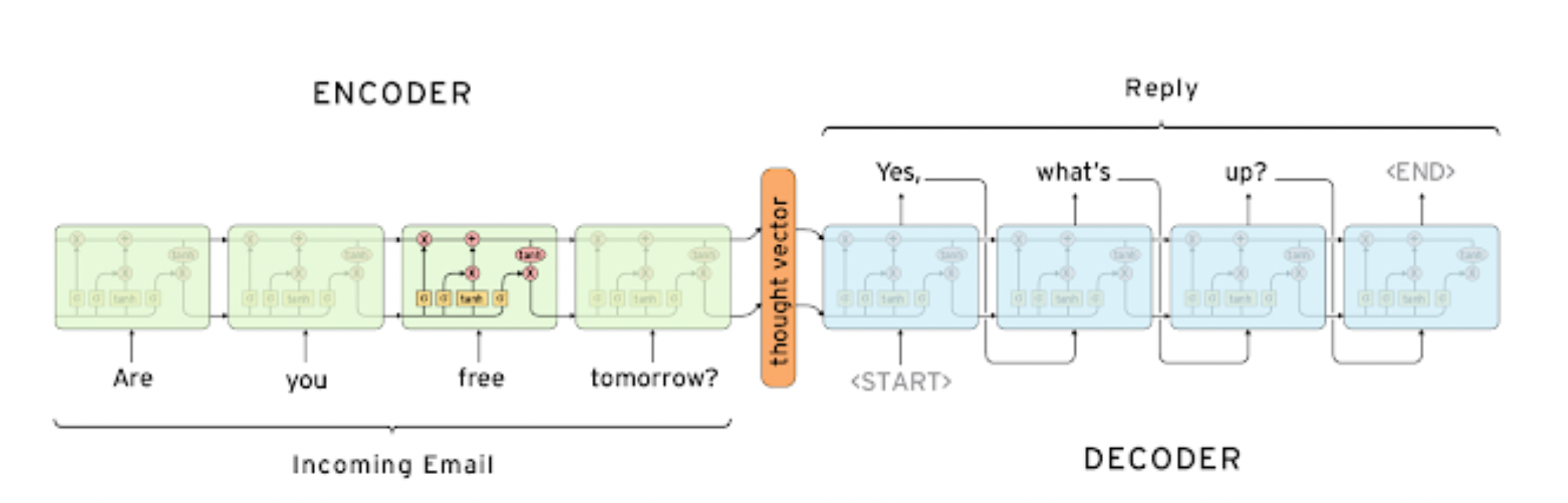
- many to many, 번역 모델에 사용
- 단어 시퀀스를 입력으로 받고 단어 시퀀스를 출력으로 줌
- 인코더 - 디코더 구조
- 인코더 : 입력 문장을 모두 받음
- 디코더 : 인코더의 마지막 히든 스테이트 벡터와 sos 를 입력으로 하여 단어 시퀀스 출력, 마지막에 eos 가 들어오면 종료
- LSTM 사용
- 문제점
- 벡터는 크기가 고정, 입력 문장이 짧든 길든 마지막 히든 스테이트 벡터에 정보가 다 담겨야 하므로 표현에 부족함이 있음
- LSTM 으로 롱텀 디펜던시를 해결했더라도 문장이 길면 부족한 성능
- 인코더의 첫 단어와 디코더의 첫 단어를 내야 하는데 멀어서 잘 못함
Attention
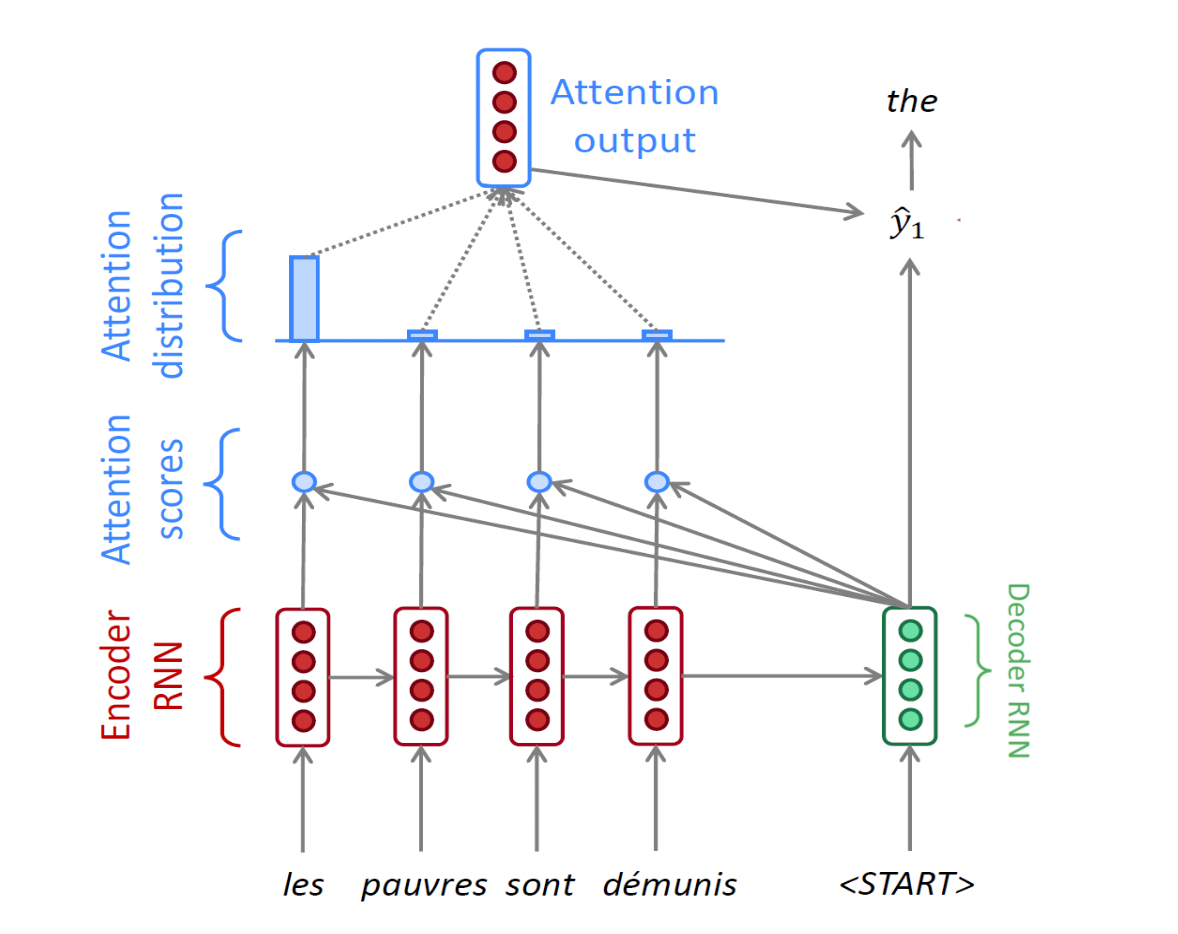
- 인코더에서 나온 마지막 h 와 디코더의 입력으로 디코더의 h 를 만들고 이를 인코더 입력 단어 각각의 히든 스테이트 벡터와 어텐션 스코어를 계산 (내적) 한 후 어텐션 분포 (소프트맥스) 를 만듦. 이 분포를 어텐션 벡터 (합이 1 인 확률분포)라고 함.
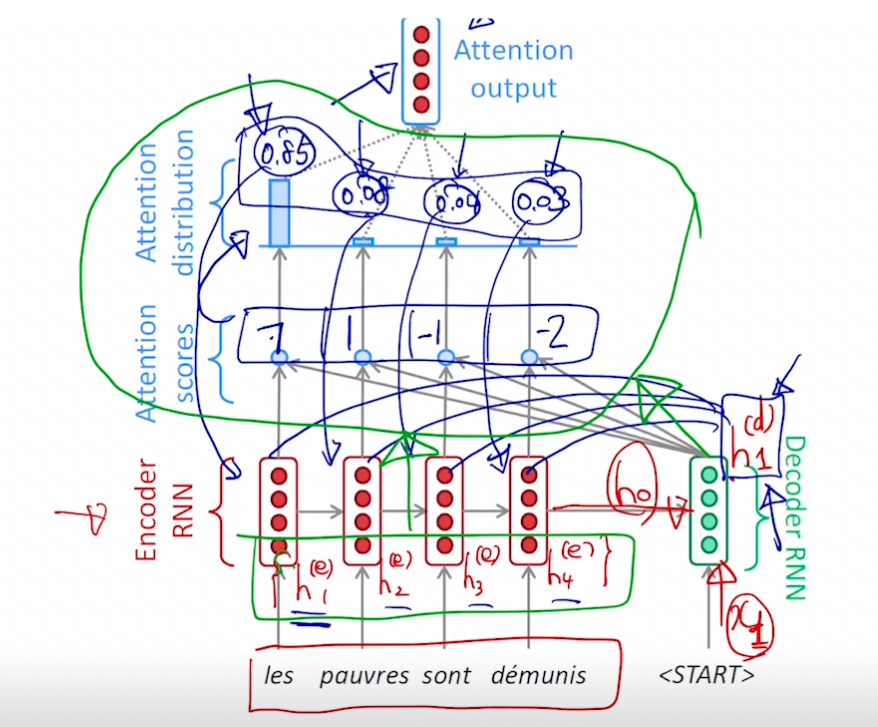
- 만들어진 어텐션 분포를 인코더의 각 히든 스테이트 벡터에 적용해서 가중 평균을 구함. 이 가중 평균은 어텐션 아웃풋, 또는 컨텍스트 벡터가 됨
- 즉, 위에서 파란 부분은 어텐션 모듈이고 그 입력으로 디코더의 h 벡터와 인코더 단어들의 각 h 벡터 세트가 들어가서 하나의 컨텍스트 벡터를 출력함
- 디코더의 h 벡터는 컨텍스트 벡터와 concat 되어 단어 예측에 사용
- 디코더의 히든 스테이트 벡터는 어텐션을 만드는 역할과 출력 단어를 만드는 역할을 수행함. 역전파 과정에서는 예측 단어가 실제 단어와 다르면 어텐션의 웨이트들과 디코더의 웨이트는 같이 수정됨.
- 학습에는 Teacher forcing 함, ground truth 를 디코더의 입력으로 넣음. 하지만 Teacher forcing 을 안했을 때 regularlization 이 잘되므로 초반에 Teacher forcing 사용
Q. 컨텍스트 벡터는 같은게 계속 갱신되는거겠지? 그 전에 어텐션 벡터 (분포) 는 계속 갱신되는거겠지?
→ 갱신이 아니라 어텐션은 그냥 계산해서 디코더 스텝 단계에서 빼주는 역할
Different Attention Mechanism
-
디코더의 h 벡터와 인코더의 각 h 벡터로 어텐션 구하는 법
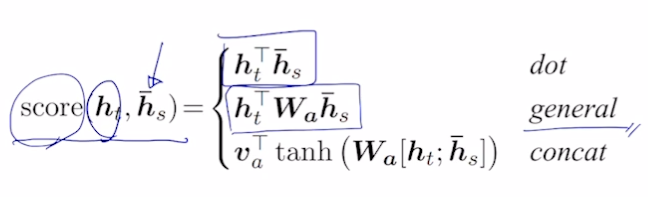
-
general
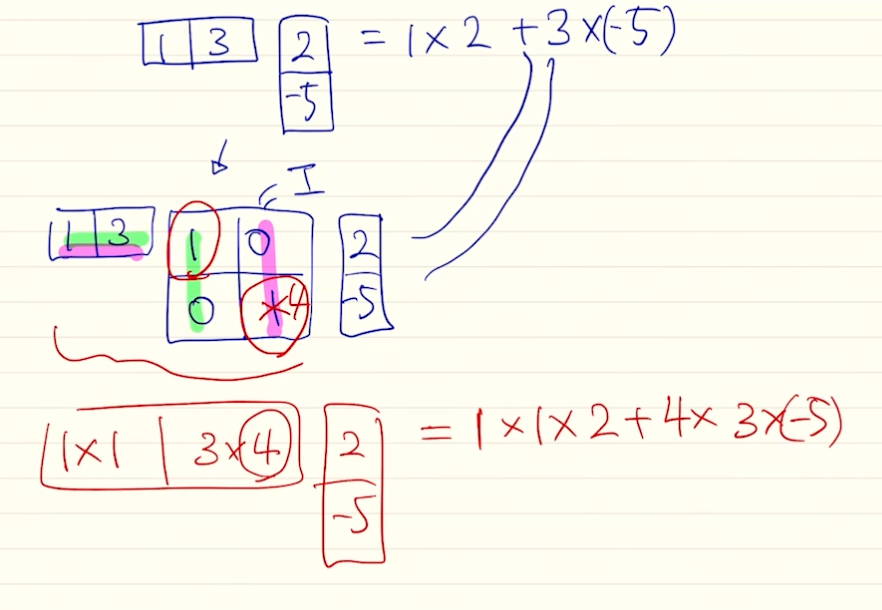
- 벡터끼리 곱을 하는 내적에서 항등행렬을 가운데 곱해도 결과는 그대로임. 여기서 항등행렬의 값을 변형시키는 방식 사용 가능 → 가중치가 됨
- 항등행렬말고 이 행렬의 값을 a, b, c, d 로 변형시키면 내적이라는 단순한 계산을 더 확장시켜 어텐션을 구할 수 있게 해줌
-
concat
- 디코더의 h 와 인코더의 h 를 통해 스칼라를 구해야 함. 이 때, 내적 말고 MLP 로 해결하려 함. 두 벡터를 concat 하고 MLP 수행해서 스칼라 구함.
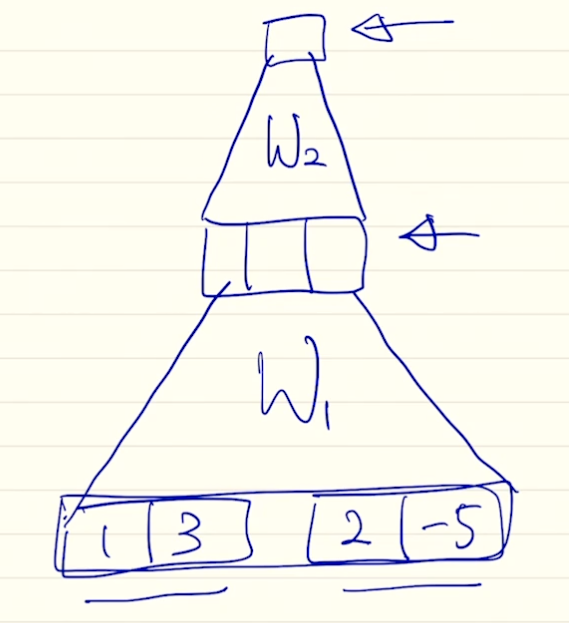
- $W_a$ 는 첫 번째 웨이트, $v_a^T$ 는 두 번째 웨이트
- 이 파라미터들은 전체 역전파 과정에서 학습됨
어텐션 장점
- NMT 기계번역 분야에서 성능 많이 높임
- 디코더가 입력의 어느 부분에 초점을 맞출지 알게됨
- 문장이 길수록 초반 단어의 의미가 퇴색되는 bottleneck 현상 해결
- 디코더가 직접 입력 단어의 h 를 보므로
- vanishing gradient 문제 해결
- 멀리 있는 뒤에 단어부터 역전파 해오면 처음 단어 쪽 웨이트는 학습이 잘 안 되는데, 어텐션으로 지름길이 생겨서 학습 영향 끼침
- 새로운 해석을 할 수 있게 해줌
- 어텐션 분포 (어텐션 벡터) 를 조사해서 디코더가 어떤 것에 집중하는지 알 수 있음
- 언제 어떤 단어를 봐야할 지 스스로 학습함
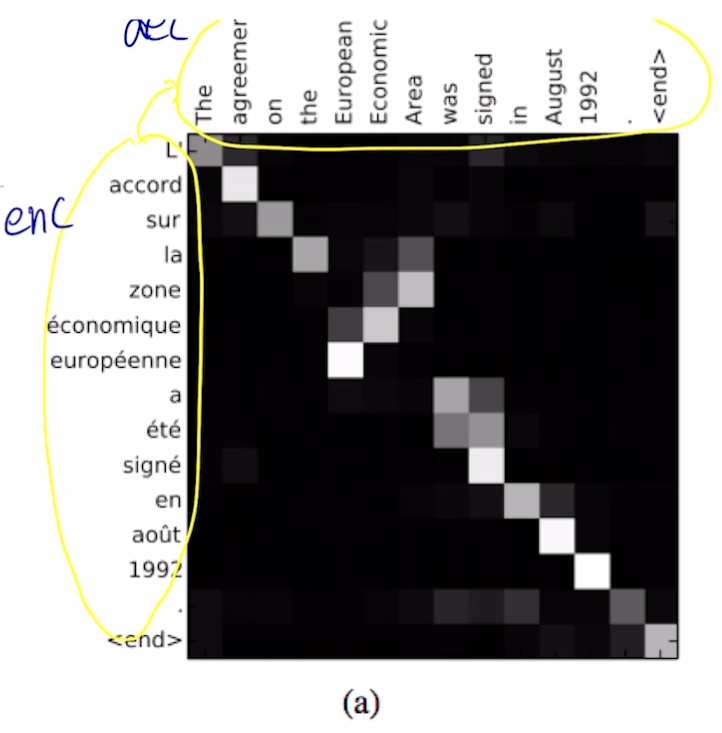
- 왼쪽이 입력, 오른쪽이 출력
- 디코더에서 어떤 입력에 집중하는지 알 수 있음
- 입력 문장과 출력 문장의 어순 차이 등도 극복 가능
Further Reading
- Sequence to sequence learning with neural networks, ICML’14
- Effective Approaches to Attention-based Neural Machine Translation, EMNLP 2015
- CS224n(2019)_Lecture8_NMT
Beam Search and BLEU
Beam Search
- 디코더에서 단어 예측할 때, 확률 기반이므로 어떤 단어를 선택할지 돕는 알고리즘
- Greedy decoding
- 현재 타임 스텝에서 확률이 가장 큰 단어 (가장 좋아보이는 단어) 를 선택
- 만약 잘못 예측했다면? 돌아가야하는데 갈 수 없음 → 다음 후보군 필요
- Exhaustive search
- 이상적으로는 전체 경우의 수를 다 따지는게 맞음
- 매 타임 스텝마다 V (보캡 사이즈) 의 t 승의 경우의 수를 구해야함 → 시간 소요 너무 큼
- 적당한 크기 후보군 선정, Beam Search
- 아이디어 : 디코더의 매 타임 스텝마다, k 개의 후보군을 정하고 가장 높은 확률 단어 선택, 후보 상황을 hypothesis 라고 부름
- k : beam size (보통 5~10 사용)
-
로그로 확률값들을 더함

- 모든 경우를 따지는 것보다는 정확하지 않지만 훨씬 효율적임
-
예시
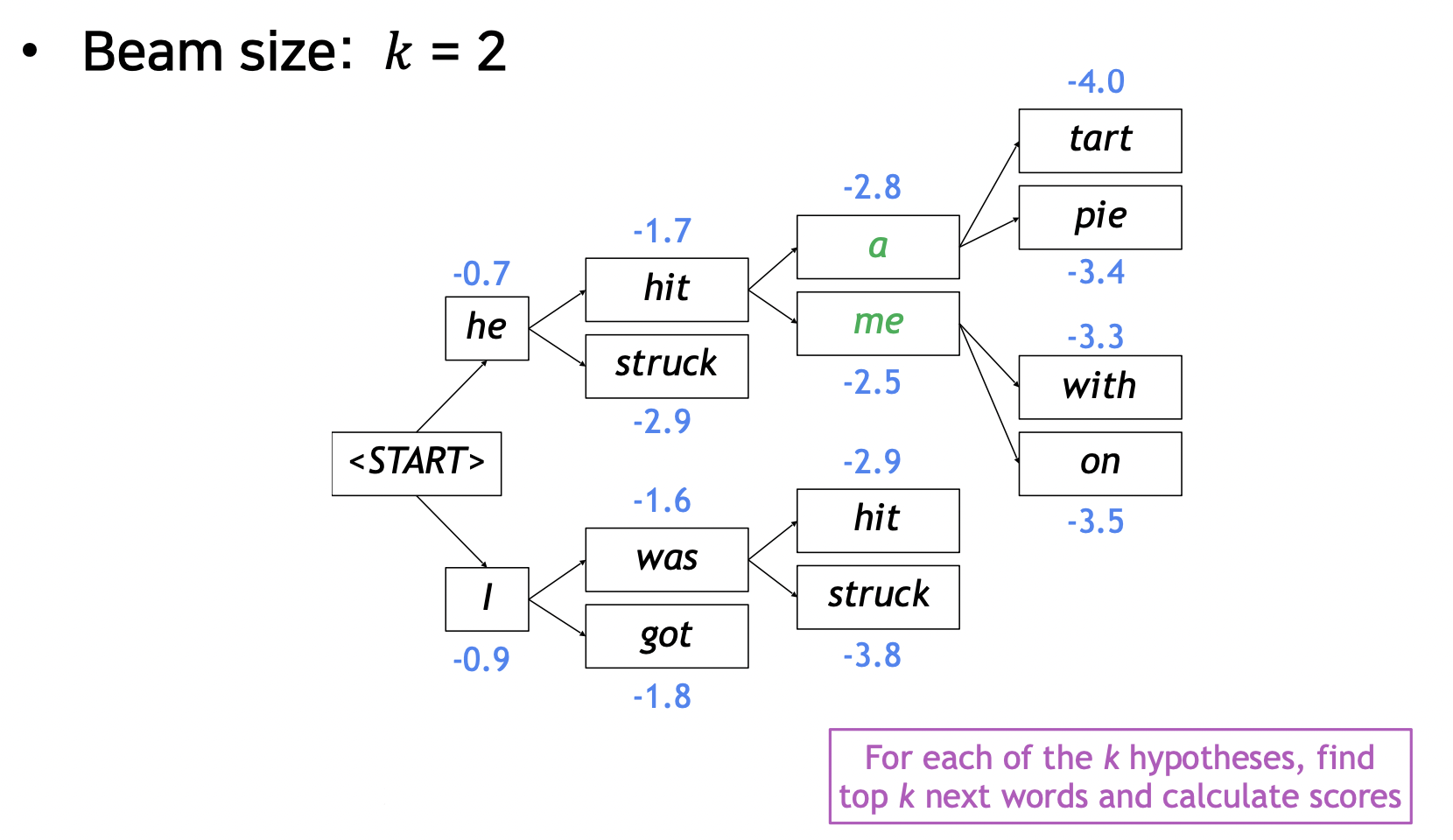
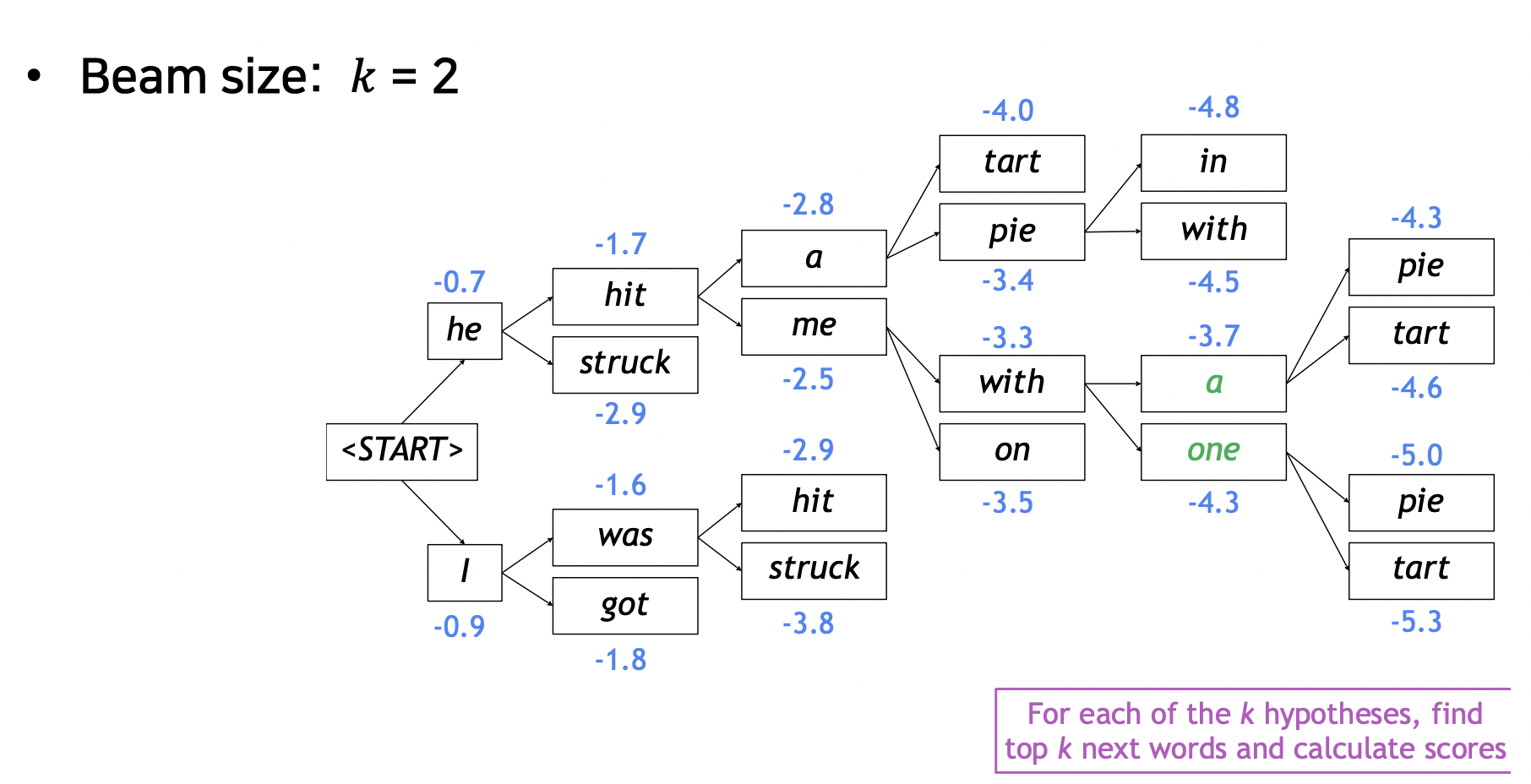
- 매 타임 스텝마다 k 개 단어를 뽑고 각 경우의 확률을 구함
- 언제 빔서치가 멈추는가?
- 각 가정은 END 토큰을 만나면 멈춤
- 멈춘 가정들의 결과를 따로 저장해 둠
- 빔서치가 멈추는 경우는 정해둔 타임스텝 T 까지만 디코딩해서 멈추거나 n 개의 가설이 완료되면 멈춤
- 완성된 가설들 중 가장 높은 점수를 지닌 가설을 선택, log 결합확률분포로 구함
- 가설의 길이가 짧을수록 점수가 높다는 문제가 있음 (항상 - 값을 더해주므로 긴 가설은 점수가 낮음)
- 공평하게 비교하기 위해 각 가설의 길이로 Normalize 진행

BLEU score
- 문장 예측 결과의 성능을 측정하는 지표
- 기존 방법들의 문제점
- 단어가 맞는지 칸칸이 비교하는 방법의 경우, 잘 번역했어도 한 두 단어가 추가, 누락된 경우 낮은 정확도가 나옴
- 정답 : I love you, 예측 : My I love you ⇒ 칸칸이 비교하므로 0% 정확도
- 다른 방법, F-measure
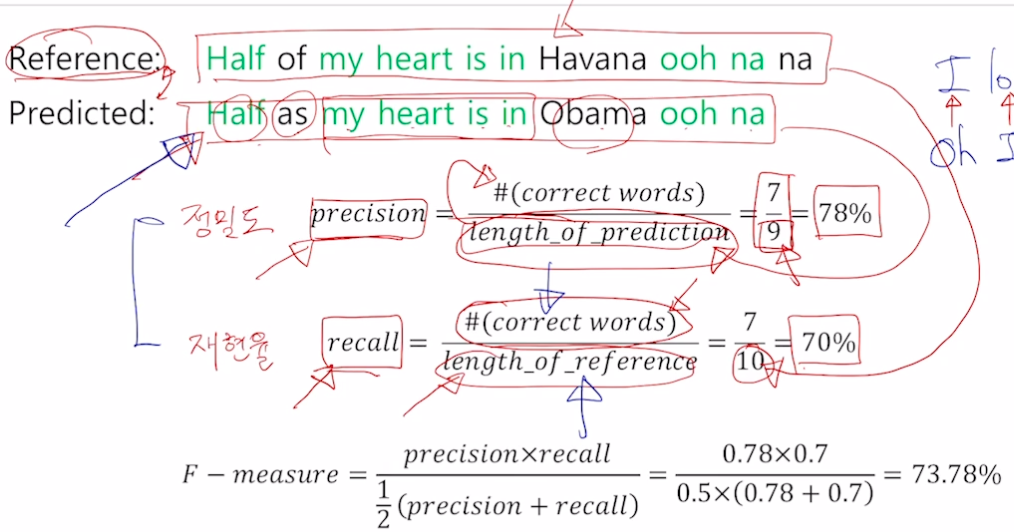
- 정밀도 : 예측된 결과가 나왔을 때 실질적으로 느끼는 정확도
- 재현율 : 전체 결과 중 예측 결과로 나오지 않은 누락 정보를 알 수 있음 (아비터의 리콜처럼 소환 기능, 누락되지 않게 소환해야 리콜 잘한 것)
- 위 두 값을 평가하기 위해 F-measure (조화평균, 여기서는 역수로 안더하는듯) 사용
- 산술평균 (더하고 나누기 개수) ≥ 기하평균 (곱하고 루트 개수) ≥ 조화평균 (역수 더하고 개수로 나누고 다시 전체 역수)
-
문제점

- 말이 되지 않는 문장인데 점수가 높음
- 단어가 맞는지 칸칸이 비교하는 방법의 경우, 잘 번역했어도 한 두 단어가 추가, 누락된 경우 낮은 정확도가 나옴
- BiLingual Evaluation Understudy (BLEU)
- 개별 단어 레벨에서 얼마나 겹치냐 + N-gram (얼마나 연속으로 맞는지) 반영 (N 은 1~4 모두 사용)
- 정밀도만 고려하고 재현율은 사용하지 않음 (정밀도의 특성 때문, 번역 결과만 보고 고려하기 때문)

- brevity penalty 는 실제 문장보다 짧게 문장을 뽑아내면 점수를 낮춰주고, 너무 많아지면 1 로만 계산하기 위해 사용
- 산술 평균보다는 작게 만들고 싶고, 조화 평균은 너무 작은 값에 치중하므로 기하 평균 사용
-
예시

Further Reading
Further Question
- BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까요?
Seq2Seq 구현
필요 패키지 import
- 필요 패키지 import
데이터 전처리
- 전체 단어 수 100, src_data 와 trg_data 가 대응되도록 데이터 준비
- trg_data 에 sos 와 eos 를 붙여 전처리
- src 와 trg 데이터의 최대 길이에 맞게 패딩 넣기
- 각각 src_batch, trg_batch 로 묶기
-
PackedSequence 사용을 위해 source data 길이 기준으로 정렬
src_batch_lens, sorted_idx = src_batch_lens.sort(descending=True) src_batch = src_batch[sorted_idx] trg_batch = trg_batch[sorted_idx] trg_batch_lens = trg_batch_lens[sorted_idx]
Encoder 구현
- 입력 데이터를 받아서 마지막 히든 스테이트 벡터를 만드는 역할
-
임베딩 → 양방향 GRU → Linear (인코더의 양방향 사이즈에서 디코더의 단방향 사이즈로 줄이기 위해)
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_size) self.gru = nn.GRU( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False, dropout=dropout ) self.linear = nn.Linear(num_dirs * hidden_size, hidden_size) def forward(self, batch, batch_lens): # batch: (B, S_L), batch_lens: (B) # d_w: word embedding size batch_emb = self.embedding(batch) # (B, S_L, d_w) batch_emb = batch_emb.transpose(0, 1) # (S_L, B, d_w) packed_input = pack_padded_sequence(batch_emb, batch_lens) h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers*num_dirs, B, d_h) = (4, B, d_h) packed_outputs, h_n = self.gru(packed_input, h_0) # h_n: (4, B, d_h) outputs = pad_packed_sequence(packed_outputs)[0] # outputs: (S_L, B, 2d_h) forward_hidden = h_n[-2, :, :] backward_hidden = h_n[-1, :, :] hidden = self.linear(torch.cat((forward_hidden, backward_hidden), dim=-1)).unsqueeze(0) # (1, B, d_h) return outputs, hidden
Decoder 구현
- 인코더는 입력 단어를 그냥 넣어주면 되는데 디코더는 출력 단어를 넣어야하므로 구현이 조금 달라짐
- 인코더에서는 입력 차원 크기가 (B, S_L) 이었는데 디코더는 (B) 로 한 단어만 사용하도록 구현함
-
밖에서 호출할 때 출력 단어를 다시 넣어주는 구조
class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_size) self.gru = nn.GRU( input_size=embedding_size, hidden_size=hidden_size, ) self.output_layer = nn.Linear(hidden_size, vocab_size) def forward(self, batch, hidden): # batch: (B), hidden: (1, B, d_h) batch_emb = self.embedding(batch) # (B, d_w) batch_emb = batch_emb.unsqueeze(0) # (1, B, d_w) outputs, hidden = self.gru(batch_emb, hidden) # outputs: (1, B, 2d_h), hidden: (1, B, d_h) # V: vocab size outputs = self.output_layer(outputs) # (1, B, V) return outputs.squeeze(0), hidden
Seq2seq 모델 구축
-
encoder 와 decoder 사용
class Seq2seq(nn.Module): def __init__(self, encoder, decoder): super(Seq2seq, self).__init__() self.encoder = encoder self.decoder = decoder def forward(self, src_batch, src_batch_lens, trg_batch, teacher_forcing_prob=0.5): # src_batch: (B, S_L), src_batch_lens: (B), trg_batch: (B, T_L) _, hidden = self.encoder(src_batch, src_batch_lens) # hidden: (1, B, d_h) # sos 를 첫 입력으로 사용 input_ids = trg_batch[:, 0] # (B) batch_size = src_batch.shape[0] outputs = torch.zeros(trg_max_len, batch_size, vocab_size) # (T_L, B, V) for t in range(1, trg_max_len): decoder_outputs, hidden = self.decoder(input_ids, hidden) # decoder_outputs: (B, V), hidden: (1, B, d_h) outputs[t] = decoder_outputs _, top_ids = torch.max(decoder_outputs, dim=-1) # top_ids: (B) input_ids = trg_batch[:, t] if random.random() > teacher_forcing_prob else top_ids return outputs
모델 사용해보기
- 학습
- 모델을 통해 outputs 를 얻음
- outputs = seq2seq(src_batch, src_batch_lens, trg_batch)
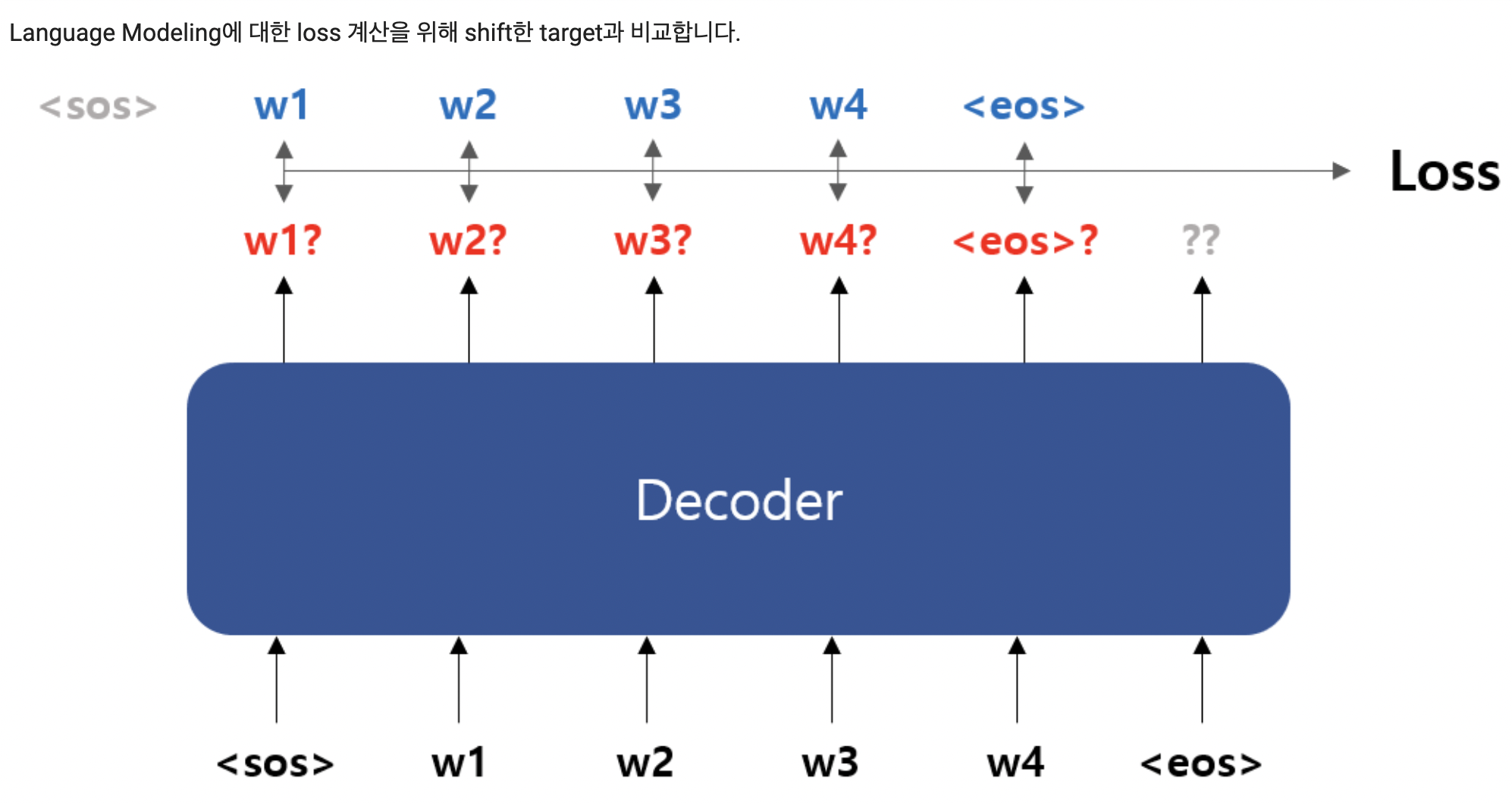
- eos 를 넣어서 나온 결과는 관심 없으므로 제거 (shift)
- 반대로 정답 (trg_batch) 의 sos 부분은 필요 없으므로 제거
loss_function = nn.CrossEntropyLoss() preds = outputs[1:, :, :].transpose(0, 1) # (B, T_L-1, V) loss = loss_function(preds.contiguous().view(-1, vocab_size), trg_batch[:,1:].contiguous().view(-1, 1).squeeze(1)) print(loss)- output 과 정답을 이용해 loss (크로스 엔트로피) 비교
- loss 구했으니까 backprop, step 진행해서 학습하면 됨
- 추정
- src_batch 를 인코더에 넣고 나온 h 와 sos 로 추정
- 이 때 나온 실제 출력값으로 다음 스텝 진행
- eos 나오면 종료
Seq2Seq with Attention 구현
필요 패키지 import
데이터 전처리
Encoder 구현
-
이제는 어텐션을 위해 모든 hidden state vectors 가 필요함
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_size) self.gru = nn.GRU( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False, dropout=dropout ) self.linear = nn.Linear(num_dirs * hidden_size, hidden_size) def forward(self, batch, batch_lens): # batch: (B, S_L), batch_lens: (B) # d_w: word embedding size batch_emb = self.embedding(batch) # (B, S_L, d_w) batch_emb = batch_emb.transpose(0, 1) # (S_L, B, d_w) packed_input = pack_padded_sequence(batch_emb, batch_lens) h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers*num_dirs, B, d_h) = (4, B, d_h) packed_outputs, h_n = self.gru(packed_input, h_0) # h_n: (4, B, d_h) outputs = pad_packed_sequence(packed_outputs)[0] # outputs: (S_L, B, 2d_h) outputs = torch.tanh(self.linear(outputs)) # (S_L, B, d_h) forward_hidden = h_n[-2, :, :] backward_hidden = h_n[-1, :, :] hidden = torch.tanh(self.linear(torch.cat((forward_hidden, backward_hidden), dim=-1))).unsqueeze(0) # (1, B, d_h) return outputs, hidden
Dot-product Attention 구현
- 위에서 배운 어텐션 방법 중 내적 방법
class DotAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, decoder_hidden, encoder_outputs): # (1, B, d_h), (S_L, B, d_h)
query = decoder_hidden.squeeze(0) # (B, d_h)
key = encoder_outputs.transpose(0, 1) # (B, S_L, d_h)
energy = torch.sum(torch.mul(key, query.unsqueeze(1)), dim=-1) # (B, S_L)
attn_scores = F.softmax(energy, dim=-1) # (B, S_L)
attn_values = torch.sum(torch.mul(encoder_outputs.transpose(0, 1), attn_scores.unsqueeze(2)), dim=1) # (B, d_h)
return attn_values, attn_scores
- attn_scores : 어텐션 벡터
- attn_values : 컨텍스트 벡터
Decoder 구현
- attention 추가
- Linear 에서 디코더의 h 와 어텐션의 컨텍스트 벡터 사이즈를 concat 해서 2*hidden_size 가 됨
class Decoder(nn.Module):
def __init__(self, attention):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.attention = attention
self.rnn = nn.GRU(
embedding_size,
hidden_size
)
self.output_linear = nn.Linear(2*hidden_size, vocab_size)
def forward(self, batch, encoder_outputs, hidden): # batch: (B), encoder_outputs: (L, B, d_h), hidden: (1, B, d_h)
batch_emb = self.embedding(batch) # (B, d_w)
batch_emb = batch_emb.unsqueeze(0) # (1, B, d_w)
outputs, hidden = self.rnn(batch_emb, hidden) # (1, B, d_h), (1, B, d_h)
attn_values, attn_scores = self.attention(hidden, encoder_outputs) # (B, d_h), (B, S_L)
concat_outputs = torch.cat((outputs, attn_values.unsqueeze(0)), dim=-1) # (1, B, 2d_h)
return self.output_linear(concat_outputs).squeeze(0), hidden # (B, V), (1, B, d_h)
Seq2seq 모델 구축
- 인코더의 히든 벡터들을 디코더에 넣어 어텐션을 진행함
class Seq2seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src_batch, src_batch_lens, trg_batch, teacher_forcing_prob=0.5):
# src_batch: (B, S_L), src_batch_lens: (B), trg_batch: (B, T_L)
encoder_outputs, hidden = self.encoder(src_batch, src_batch_lens) # encoder_outputs: (S_L, B, d_h), hidden: (1, B, d_h)
input_ids = trg_batch[:, 0] # (B)
batch_size = src_batch.shape[0]
outputs = torch.zeros(trg_max_len, batch_size, vocab_size) # (T_L, B, V)
for t in range(1, trg_max_len):
decoder_outputs, hidden = self.decoder(input_ids, encoder_outputs, hidden) # decoder_outputs: (B, V), hidden: (1, B, d_h)
outputs[t] = decoder_outputs
_, top_ids = torch.max(decoder_outputs, dim=-1) # top_ids: (B)
input_ids = trg_batch[:, t] if random.random() > teacher_forcing_prob else top_ids
return outputs
모델 사용해보기
- 학습 하여 추정
Concat Attention (=Bahdanau Attention) 구현
- 디코더 h 를 S_L 크기로 중복시켜서 인코더의 h 들과 concat
- concat 으로 2*h 이므로 w 레이어에서 h 로 바꿔줌
- v 에서 h → 1 (어텐션 벡터, attn_scores) 로 바꿔줌
- attn_scores 를 평균내서 attn_values (컨텍스트 벡터) 구함
class ConcatAttention(nn.Module):
def __init__(self):
super().__init__()
self.w = nn.Linear(2*hidden_size, hidden_size, bias=False)
self.v = nn.Linear(hidden_size, 1, bias=False)
def forward(self, decoder_hidden, encoder_outputs): # (1, B, d_h), (S_L, B, d_h)
src_max_len = encoder_outputs.shape[0]
decoder_hidden = decoder_hidden.transpose(0, 1).repeat(1, src_max_len, 1) # (B, S_L, d_h)
encoder_outputs = encoder_outputs.transpose(0, 1) # (B, S_L, d_h)
concat_hiddens = torch.cat((decoder_hidden, encoder_outputs), dim=2) # (B, S_L, 2d_h)
energy = torch.tanh(self.w(concat_hiddens)) # (B, S_L, d_h)
attn_scores = F.softmax(self.v(energy), dim=1) # (B, S_L, 1)
attn_values = torch.sum(torch.mul(encoder_outputs, attn_scores), dim=1) # (B, d_h)
return attn_values, attn_scores
Decoder
- dot-product 의 디코더는 rnn 먼저 돌고 그 벡터로 어텐션을 했다면, 여기서는 어텐션을 먼저하고 rnn 진행
class Decoder(nn.Module):
def __init__(self, attention):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.attention = attention
self.rnn = nn.GRU(
embedding_size + hidden_size,
hidden_size
)
self.output_linear = nn.Linear(hidden_size, vocab_size)
def forward(self, batch, encoder_outputs, hidden): # batch: (B), encoder_outputs: (S_L, B, d_h), hidden: (1, B, d_h)
batch_emb = self.embedding(batch) # (B, d_w)
batch_emb = batch_emb.unsqueeze(0) # (1, B, d_w)
attn_values, attn_scores = self.attention(hidden, encoder_outputs) # (B, d_h), (B, S_L)
concat_emb = torch.cat((batch_emb, attn_values.unsqueeze(0)), dim=-1) # (1, B, d_w+d_h)
outputs, hidden = self.rnn(concat_emb, hidden) # (1, B, d_h), (1, B, d_h)
return self.output_linear(outputs).squeeze(0), hidden # (B, V), (1, B, d_h)
Seq2Seq Model Training with Fairseq
Fairseq
- pytorch 를 만드는 facebook 의 오픈소스 프로젝트로 시퀀스 모델링 (번역, 요약, 문장 생성 등) 학습을 도움
- Library reference
- tasks
- translation task와 language modeling task가 있고 나머지 sequence를 다루는 task는 register_task() function decorator를 이용해 등록할 수 있습니다.
- models
- 모델은 CNN, LSTM, Transformer 기반 모델들이 분류가 되어 있습니다. transformer 모델쪽 코드가 꼼꼼히 잘되어 있습니다. 새로운 모델을 등록하기 위해서는 register_model() function decorator를 이용할 수 있습니다.
- criterions
- 모델 학습을 위한 다양한 loss들이 구현되어 있습니다.
- optimizers
- 모델 학습을 위한 다양한 optimizer들이 구현되어 있습니다.
- learning rate schedulers
- 모델의 더 나은 학습을 위한 다양한 learning rate scheduler들이 구현되어 있습니다.
- data loading and utilities
- 전처리 및 데이터 관련 다양한 class들이 구현되어 있습니다.
- modules
- 앞의 6군데에 속하지 못한(?) 다양한 모듈들이 구현되어 있습니다.
- tasks
-
Command-line Tools
https://fairseq.readthedocs.io/en/latest/command_line_tools.html
- fairseq-preprocess
- 데이터 학습을 위한 vocab을 만들고 data를 구성합니다.
- fairseq-train
- 여러 gpu 또는 단일 gpu에서 모델을 학습시킵니다.
- fairseq-generate
- 학습된 모델을 이용해 전처리된 데이터를 번역합니다.
- fairseq-interactive
- 학습된 모델을 이용해 raw 데이터를 번역합니다.
- fairseq-score
- 학습된 모델이 생성한 문장과 정답 문장을 비교해 bleu score를 산출합니다.
- fairseq-eval-lm
- language model을 평가할 수 있는 command입니다.
- fairseq-preprocess
마스터 클래스
주재걸 교수님 (1)
세부 연구분야 선정 어떤 기준으로 결정하셨나요? P stage 에서 주제 선정할 때 팁이 있을까요?
- 교수님랩 현재는 비전 50, nlp 25, 시계열 25
- 비전이 연구하고 공부하기 더 수월한 분야, 발전도 빠르고 본인이 뭔가 할 수 있으나 사람이 많아서 경쟁이 치열
- nlp 쪽은 대규모 모델 프리 트레이닝쪽으로 가고 있어서 인프라 확충이 힘든 부분이 있음, NLP 쪽 사람이 적어서 시장에서는 인기 더 좋음
- 더 끌리는 분야 가라~
신입 AI 개발자에게 요구하는 역량은 어느정도일까요? 이정도는 알고 취업을 하는게 좋겠다라는 기준이 있나요?
- 학교에 있다보니 산업에서 요구하는 역량 정확히는 모르겠음
- 네이버같은 곳은 서류, 코테 (AI 관련, 알고리즘) 요구
- 산업에서 서비스할 때는 전체 파이프라인을 다뤄야하므로 AI 모듈은 빙산의 일각이므로 앞 뒤 부분 다 잘해야 함
- 기준은 뭐 U 스테이지에서 배우는 어텐션, 트랜스포머, 백프로파게이션 등등 전부
- 최근 논문, 기술을 보고 (영어로 빨리 읽고) 빨리 구현할 줄 아는 사람
NLP 데이터를 구할 때 현업에서도 웹의 여러 텍스트를 크롤링하나요? 크롤링이 산업 현장에서 NLP 엔지이어에게 유효한 기술 스택일까요?
- 그렇다. 돈 주고 데이터 얻는 경우도 많지만, 회사 사정 등으로 직접 구해야하는 경우 많음
AI가 신기하지만 직관적이지 않아 답답합니다. 이런 부분을 어떻게 받아들이시나요? 계속 공부할 수 있는 원동력이 있나요?
- 협업의 중요성, 혼자서만 꾸준히 하기보다 여러 사람들과 같이 일해서 한 태스크를 빨리 끝내는 분위기. 공부할 때도 혼자 공부보다 마음 맞는 사람들이랑 같이 하는거 추천
GPT-3 학습은 어려워서 허가받아야하는데 개인이나 작은 단체는 어떻게 학습하고 활용할 수 있을까요? 앞으로 더 규모가 큰 모델이 나오면 어떻게 대처해야할까요?
- 풀리지 않는 문제, 핵심적인 문제
- 답은 사실 없다..? 자본력, 규묘의 경제. 잘모르겠다?
- 협업해야하지 않을까 허허
시장에서 CV 가 NLP 보다 수요가 많은거 같은데, AI 엔지니어로 NLP 분야 서비스 공부하는데 있어 무엇을 공부하고, 어떤 함정들을 조심해야할까요?
- NLP 가 더 인기 많을거라 생각, 실력있으면 가능
- 실적이나 외부 스펙 신경쓰는게 좋을듯
CS 분야 (ML 포함) 해외 유학 어떻게 생각하시나요
- 견문 넓힐 수 있어서 추천
- 우리나라도 요즘 상향 평준화돼서 좋긴함
- 미국 가면 미국 취업하기 좋음
공부할 때 밑바닥부터 할지, 탑다운으로 최신 논문 위주로 할지 고민입니다
- 선택과 집중, 밸런스 문제
- 최신 논문만 봐도 한계가 있고, 기초 공부만 해도 비효율적
프론트엔드와 AI의 결합이 가능할까요?
- 잘 안하지만 그런 프로그램이나 시스템 만들어지면 가능할듯
- cli 로 하는게 보통 더 빠르고 수월하니..
대학원을 연구가 아닌 취업이 목적이면 어떨까요? 취업에 석사 학위가 필요한 경우가 많아서요.
- 일반적으로 AI 는 대학원 기술이라는 생각이 강함. 학부과정에서 깊이 있게 다루기 쉽지 않기 때문.
- 많은 경우 회사에서 석사 이상 원하니까 대학원가는거 좋다.
- 작은 사회생활 (조직) 이므로 경험하는거 좋음
모델 이해할 때 작은 예시로 이해하는 편인데 이 공부법이 유효할까요?
- 교수님도 그렇게 이해하시는 편.
C++ 로 큰 퍼포먼스 향상이 가능할까요?
- 그렇다
자연어처리 석사생으로서 발화 생성에 관심갖고 연구. 트랜스포머 이후 NLP 트렌드가 빨리 변해 커버해야할 양이 많은데 성공적으로 석사생 마칠 팁이 있을까요
- 주변 사람들 도움 받고 일하길
랩실 선발기준
- 기초 내용 잘 아는 사람?
- 교수님 연구실 FAQ 참고
LSTM, GRU 가 트랜스포머 이후 밀렸는데 유통기한이 어느정도일까요?
- 숏텀 정보가 중요할 떄는 LSTM 이 중요한 경우도 많음
- 롱텀은 트랜스포머
피어 세션
TED 세션 - 펭귄님
펭귄님께서 이 때까지 데이터 분석과 관련된 공모전과 캐글 스터디 등을 한 경험을 공유하였다.
수업 질문
Today I Felt
부지런함
오늘 펭귄님의 TED 세션은 인상깊었다. 각종 공모전 참여에 케글 스터디까지,, 똑같이 대학교를 다녔는데 저렇게 많은 일을 했다는 것은 더 부지런하게 살았다는게 아닐까하는 생각이 들었다. 나도 나름 열심히 살았다고 생각했지만 막상 그렇지 않은 것 같기도 하다. 과거로 갈 순 없으니 지금부터라도 꾸준히 롤링해야겠다. 또한 해보지 않은 영역이라도 뭐든 도전하는 자세를 가져야지!