목차
- Recurrent Neural Network and Language Modeling
- LSTM and GRU
- Basic RNN 실습
- LSTM, GRU 실습
- Preprocessing for NMT Model
- 피어 세션
- Today I Felt
Recurrent Neural Network and Language Modeling
참고
들어가기 앞서 지난 번에 배운 RNN 첫걸음 내용도 참고하자.
Basic of RNNs
- 시퀀스 입력 데이터에 대해 현재 입력 $x_t$ 는 이전 입력값들의 계산 결과 $h_\mathit{t-1}$ 와 함께 계산되어 $h_t$ 를 뽑아낸다.
- 출력값 y 를 만들기 위해서는 h 에 대해 선형 변환 ($W_\mathit{hy}h$) 수행, 매 스텝마다 뽑아내야할 수도 있고 아닐 수도 있음 (번역 or 요약 등)
- y 는 스칼라 값을 지닌 벡터이므로 softmax 를 통해 분류 등 수행
- RNN 함수 $f_W$ 과 $W_y$ 는 모든 스텝에서 동일
-
h 의 차원 수는 사전에 정의해야 하는 하이퍼파라미터
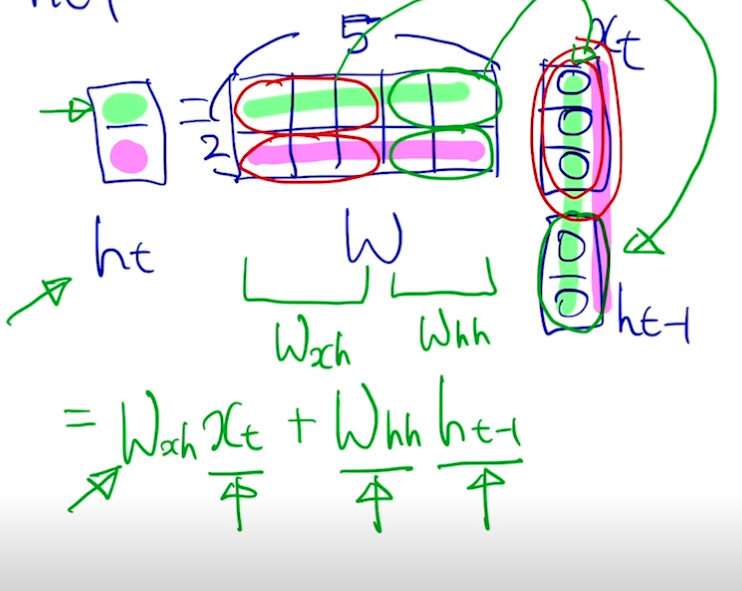
- $f_W(h_\mathit{t-1},\ x_t)$ 는 $h_\mathit{t-1},\ x_t$ 를 concat 하여 계산한다는 뜻
RNN 종류
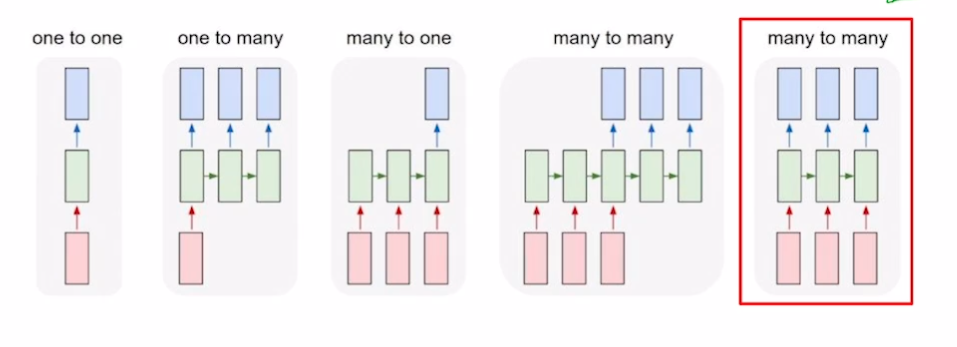
- one to one(RNN x) : 입력 1개, 출력 1개 (시퀀스 x) (점수 예측)
- one to many : 하나의 입력 (첫 스텝 제외, 나머지 스텝에서는 비어있는 입력 넣음) 으로 여러 스텝을 하며 항상 출력
- many to one : 시퀀스 입력을 스텝마다 처리하여 마지막에 결과 출력 (문장 감정 분석)
- many to many
- 시퀀스 입력과 여러 출력 (문장 번역)
- 입력, 출력 1대1 대응 (단어 품사 분석, 영상 프레임마다 어떤 장면인지 분석 등)
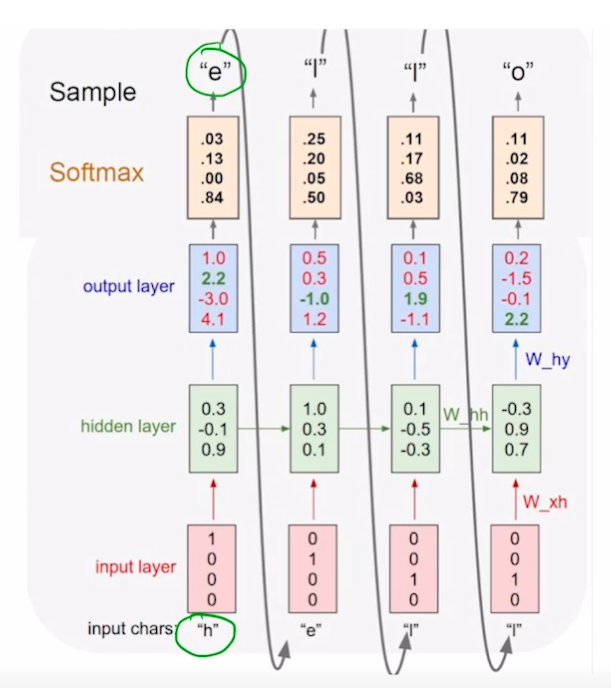
Character-level Language Model
- “hello” 단어에서 각 문자에 대해 다음 문자 예측 수행
- vocab : [h, e, l, o]
- [1, 0, 0, 0], …, [0, 0, 0, 1]
- h→e, … l→o
- $h_t = tanh(W_\mathit{hh}h_\mathit{t-1}+W_\mathit{xh}x_t+b)$
- many to many
- softmax(y_hat) 와 y 의 차를 loss 로 두어 backpropagation 수행
-
inference
BPTT
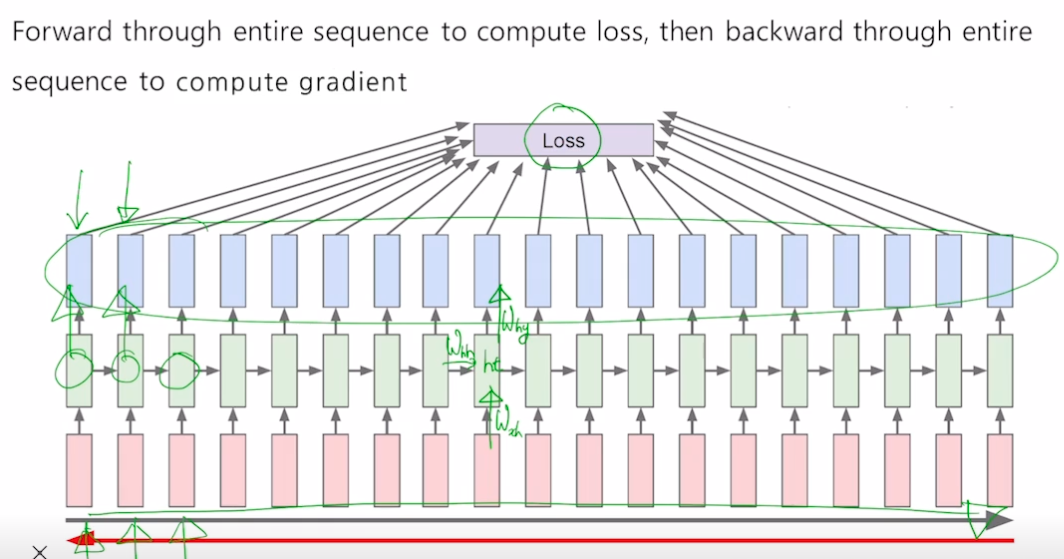
- RNN 과정이 많이 반복될 수록 backpropagation 수행 시간 많이 소요
- truncated, 특정 크기만큼만 backpropagetion 수행
How RNN Works
-
If statement cell

- if 뒤에는 빨간색이 됨, 저 부분을 담당하는 특정 dim 이 학습되었음
Vanishing/Exploding Gradient Problem in RNN
-
백프로파게이션할 때 같은 매트릭스를 매 스텝마다 곱하면 grad 가 사라지거나 넘침
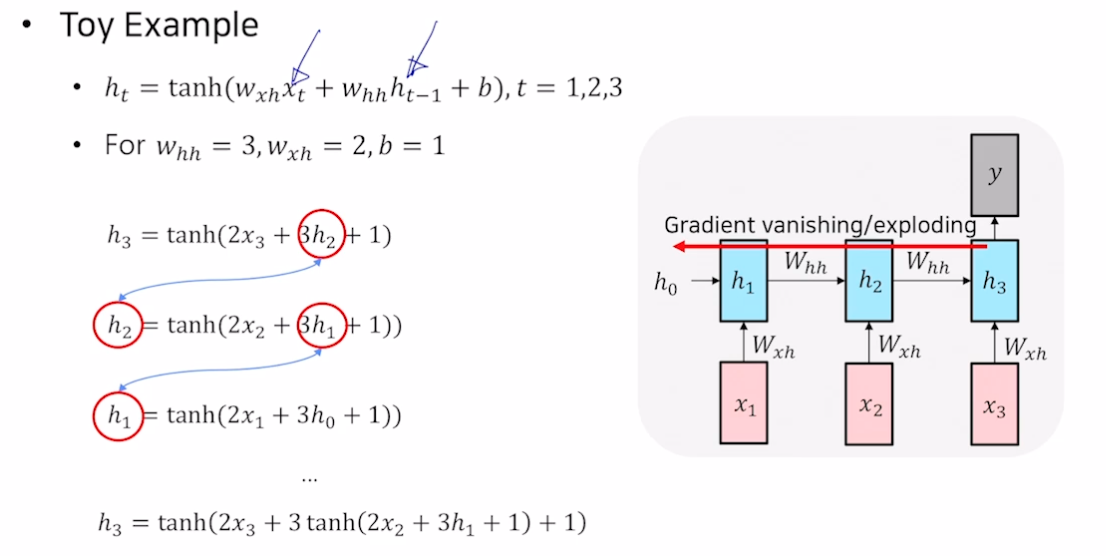
- h3 을 h1 에 대해 편미분해서 내려가다 보면, 3 이 계속 곱해짐. $W_\mathit{hh}$ 를 계속 곱하게 됨.
- 학습이 잘 안 됨
Further Reading
LSTM and GRU
LSTM (Long Short-Term Memory)
- 단기 기억을 길게 보관할 수 있도록 만든 소자
- $h_t = f_w(x_t, h_\mathit{t-1})$
- ${c_t, h_t} = LSTM(x_t, c_\mathit{t-1}, h_\mathit{t-1})$
- $c_t$ 셀 스테이트
- 조금 더 완성된 (여러가지 필요한 정보를 담고 있는) 벡터
- $h_t$ 히든 스테이트
- 셀 스테이트 벡터를 한 번 더 가공해서 노출시켜주는 벡터
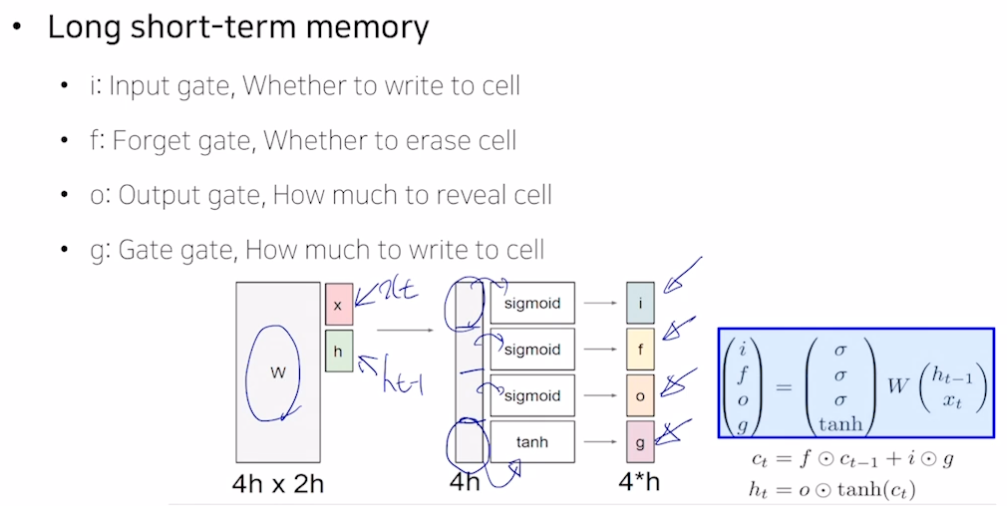
- x 와 h 는 h 차원 가져서 concat 하면 2h. 선형결합하면 2h → 4h 가 됨.
- 시그모이드를 거치면 값을 줄여줌 (e.g., 원래 값의 30% 만 보존)
- tanh를 거치면 -1~1 사이 값 가지므로 벡터를 저 사이로 변환시켜 유의미한 정보로 만듦
-
Forget gate
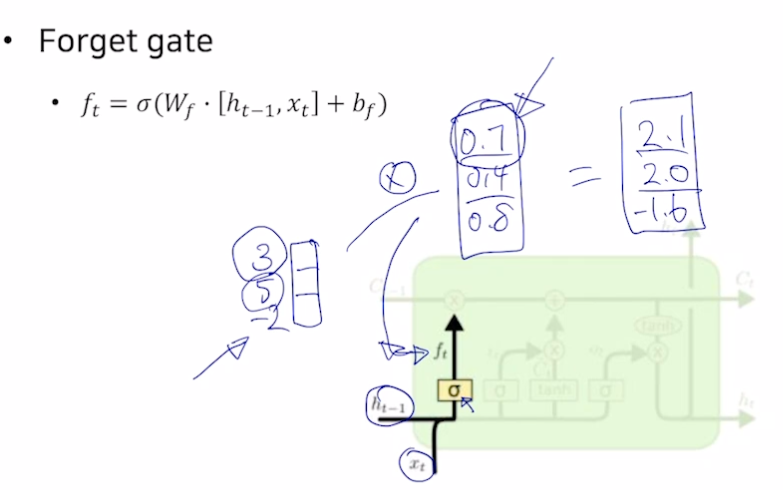
- 시그모이드를 통해 값을 버림
-
Gate gate
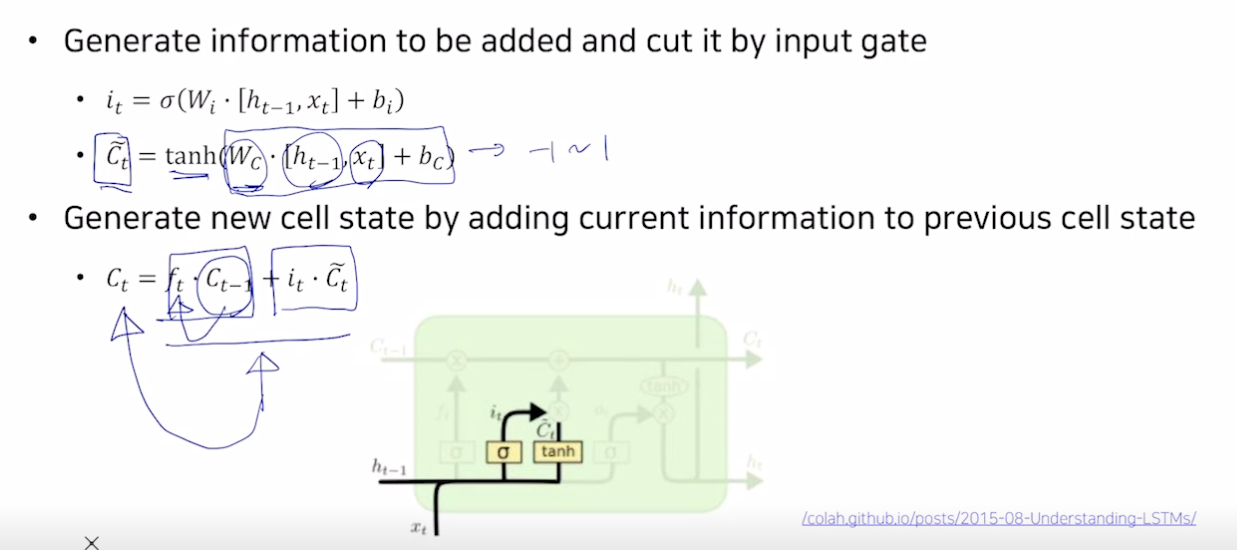
- C틸다는 tanh 를 거쳐 -1~1 로 바뀜.
- 셀 스테이트 갱신 : 덜어낸 정보 (c * forget ) 와 새로운 정보 ($i_t$ * C틸다 (한 번의 선형변환만으로 더해줄 값을 만들기 어렵기 때문에 C틸다로 값을 만들고 i 를 곱하여 값을 덜어냄)) 를 더한다.
-
Output gate
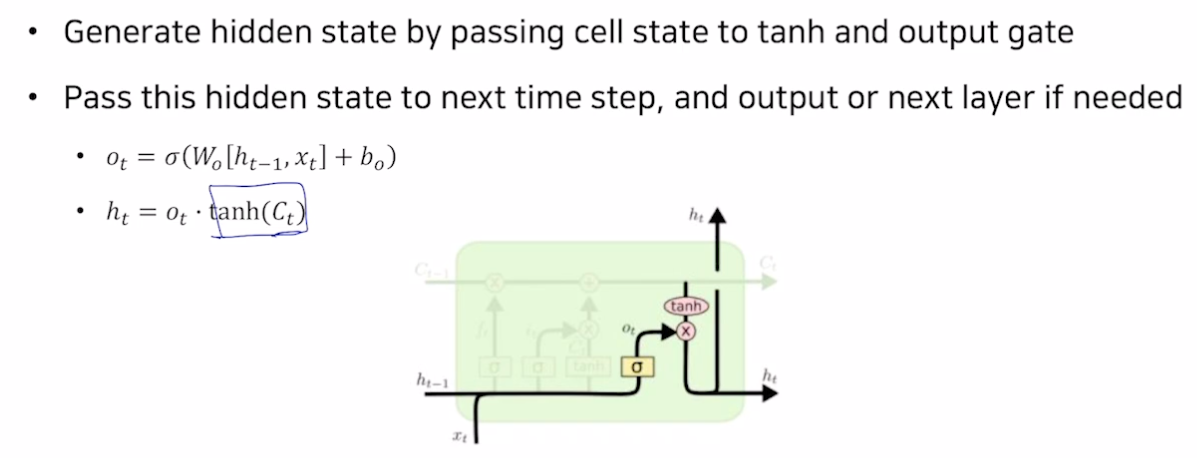
- 히든 스테이트 : 만들어진 셀 스테이트에 tanh 를 통해 정보를 만들고 o 만큼 덜어냄.
- 히든 스테이트는 많은 정보를 지닌 셀 스테이트를 조정해준 것
- 출력의 소스가 됨
GRU (Gated Recurrent Unit)
- 경량화되어 적은 메모리 소요 + 속도 빠름
- 히든 스테이트 벡터만 존재
- 전체 동작 원리는 LSTM 과 거의 비슷함
-
LSTM 에서 완전한 정보 셀 스테이트처럼 여기서는 히든 스테이트가 완전한 정보를 지녀야 함
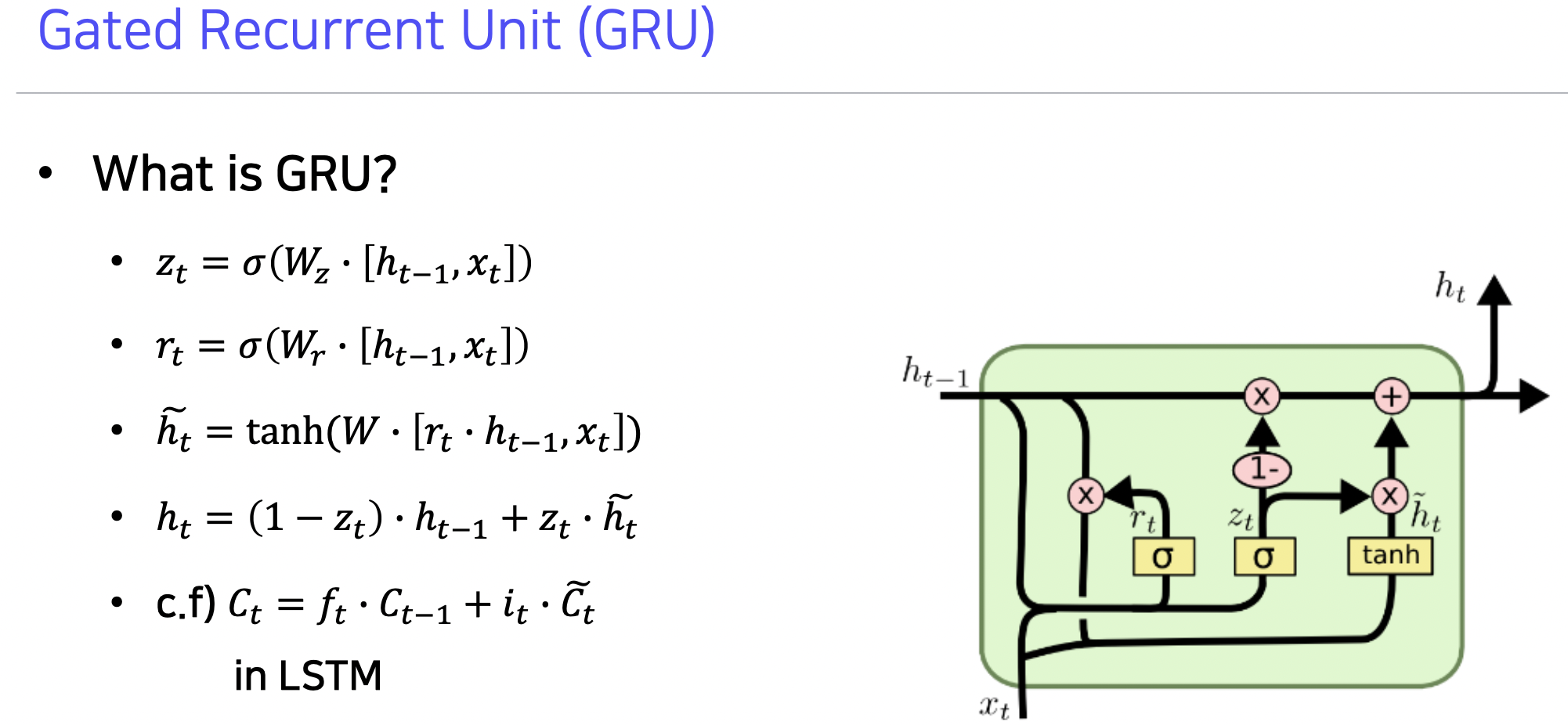
- z 는 인풋 게이트
- 구조를 보면 이전 정보 h 에는 1-z, 현재 인풋 게이트 h틸다에는 z 를 곱하여 덜어낼 것과 새로 채울 것의 비율을 맞춰줌
- 경량화됐지만 LSTM 과 비슷하거나 좋은 성능 보여줌
Backpropagation in LSTM?GRU
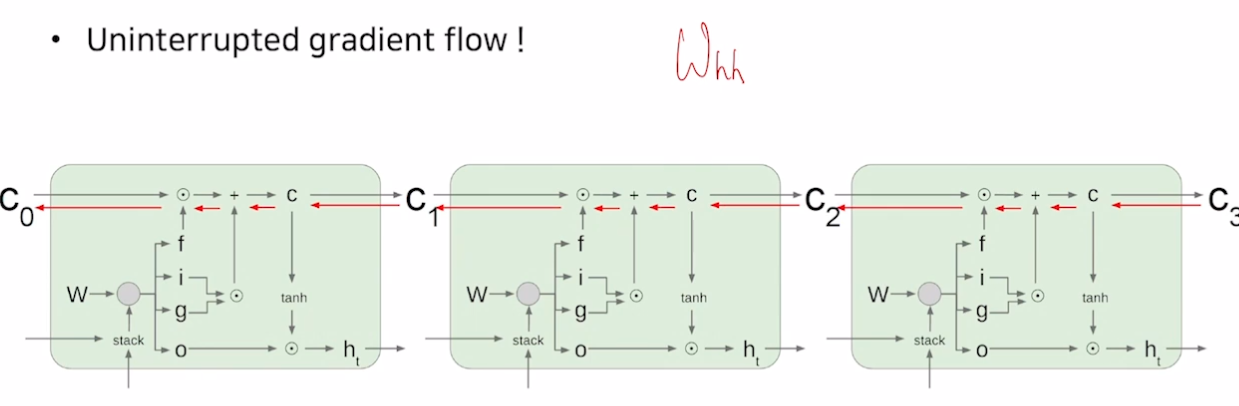
- 더 길게 grad 를 전달해줄 수 있음
요약
- RNN 은 아키텍쳐 디자인에 유연성을 더해줌
-
기본 RNN 은 간단하지만 잘 동작하지 않음
→ timestep 마다 업데이트하는 과정이 곱셈에 기반했기 때문에 gradient vanishing 문제 생김
- LSTM 과 GRU 는 덧셈 기반으로 grad 잘 전달함
Further Reading
Further Question
- BPTT 이외에 RNN/LSTM/GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법이 있을까요?
-> RTRL, EKF (확실하지 않음) - RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법이 있을까요?
-> teacher forcing (초반에는 출력 단어를 입력으로 넣지 않고 답을 입력으로 넣음)
Basic RNN 실습
필요 패키지 import
- torch, torch.nn, torch.nn.utils.rnn 의 pack_padded_sequence, pad_packed_sequence 임포트
데이터 전처리
- 보캡사이즈 100
- 모든 데이터 동일한 크기 가지도록 패딩값 설정 0
- 데이터는 문장의 단어들을 인덱스 형태로 지님
- 패딩 전처리 (가장 긴 문자열 기준으로 맞춰줌)
- 데이터 전체를 배치로 만듦 batch = torch.LongTensor(data) # (B: 배치크기, L: 문장 최대 길이)
RNN 사용해보기
- RNN 에 사용될 word embedding 을 위해 embedding layer 만듦
- embedding = nn.Embedding(vocab_size, embedding_size)
- batch_emb = embedding(batch) # (B, L, d_w)
- 모델 정의
- RNN 레이어 개수와 hdim, 단방향 or 양방향 세팅
- nn.RNN 제공, 파라미터 세팅해줄것, rnn = nn.RNN(…)
- h_0 라는 레이어 크기는 (레이어개수*방향수, 배치, 히든), 값은 제로로 세팅
- 모델에 배치 임베딩을 넣어 두 가지 결과 얻음
- hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0) # batch_emb 를 L, B, d_h 로 만들기 위해 트랜스포즈 (batch_first = True 주면 원래 모양으로 넣어도 알아서 해줌)
- hidden_states : 각 타임 스텝의 히든 스테이트 벡터
- h_n : 마지막 스텝에서 (앞의 것 포함한) 의미를 압축한 히든 스테이트 벡터
- hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0) # batch_emb 를 L, B, d_h 로 만들기 위해 트랜스포즈 (batch_first = True 주면 원래 모양으로 넣어도 알아서 해줌)
RNN 활용법
- 위에서 나온 아웃풋들을 사용해보자
- 1) 마지막 히든 스테이트를 사용하여 텍스트 분류 문제 풀기 (매니 투 원)
- 분류하고자 하는 클래스 개수만큼 리니어 수행
- 2) 각 스텝의 히든 스테이트를 사용하여 토큰 레벨 문제 풀기 (매니 투 매니)
- 원하는 클래스 개수만큼 각 단계마다 리니어 수행
- 1) 마지막 히든 스테이트를 사용하여 텍스트 분류 문제 풀기 (매니 투 원)
- 랭귀지 모델에서는 조금 다르게 사용해야 함 (아웃풋의 워드를 다시 인풋으로 넣어야 하기 때문). 현재는 결과 문장을 이미 알고 넣어주는 것 (예측해서 넣는게 아니라)
PackedSequence 사용법
- 앞에서 데이터에 패딩을 줬기 때문에 0 인 부분이 많음 → 비효율적으로 패딩 부분과 연산해버림
- 개선 : 길이순으로 데이터를 내림차순 정렬
- sorted_lens, sorted_idx = batch_lens.sort(descending=True)
- sorted_batch = batch[sorted_idx]
→ 패딩 전까지만 연산 수행 (PackedSequence 역할)
- packed_batch = pack_padded_sequence(emb, sorted_lens) 하면 PackedSequence 객체로 반환 # 패딩은 계산 안해줌, 차원 줄어듦
- outputs, outputs_lens = pad_packed_sequence(packed_outputs) # 원래 차원으로 돌려줌
LSTM, GRU 실습
필요 패키지 import, 데이터 전처리
- 위와 동일
LSTM 사용
- cell state 필요. hidden state 모양과 같음
- 임베딩 레이어, lstm = nn.LSTM(…), h_0, c_0 생성
- 배치 임베딩
- packed_batch = pack_padded_sequence…
- packed_outputs, (h_n, c_n) = lstm(packed_batch, (h_0, c_0))
- outputs, output_lens = pad_packed_sequence(packed_outputs)
GRU 사용
- cell state 없이 hidden state 만 있음
- GRU 를 사용하여 랭귀지 모델 태스크 수행
- 이 모델은 teacher forcing 하지 않음 (출력 단어를 입력으로 넣지 않고 답을 입력으로 넣는 방식)
# gru 생성
gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True if num_dirs > 1 else False
)
# 출력 레이어 생성
output_layer = nn.Linear(hidden_size, vocab_size)
# 입력에 사용할 첫 단어 추출
input_id = batch.transpose(0, 1)[0, :] # (B)
hidden = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (1, B, d_h)
# 학습
for t in range(max_len):
# 한 단어이므로 셀 하나만 통과함
input_emb = embedding(input_id).unsqueeze(0) # (1, B, d_w)
output, hidden = gru(input_emb, hidden) # output: (1, B, d_h), hidden: (1, B, d_h)
# 다음 단어를 예측함
# V: vocab size
output = output_layer(output) # (1, B, V)
probs, top_id = torch.max(output, dim=-1) # probs: (1, B), top_id: (1, B)
print("*" * 50)
print(f"Time step: {t}")
print(output.shape)
print(probs.shape)
print(top_id.shape)
# 예측 단어를 다음 입력으로 사용
input_id = top_id.squeeze(0) # (B)
- 현재는 max_len 만큼 문장을 돌지만, seq-seq 에서는 eos 오면 문장 끝냄.
양방향 및 여러 layer 사용
- 양방향 : 역방향까지 이해를 하면, 순방향 때 파악하지 못했던 것들을 캐치해서 표현력이 좋아짐
- 양방향을 concat 해서 사용
num_layers = 2
num_dirs = 2
dropout=0.1
gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=dropout,
bidirectional=True if num_dirs > 1 else False
)
# d_w: word embedding size, num_layers: layer의 개수, num_dirs: 방향의 개수
batch_emb = embedding(batch) # (B, L, d_w)
h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers * num_dirs, B, d_h) = (4, B, d_h)
packed_batch = pack_padded_sequence(batch_emb.transpose(0, 1), batch_lens)
packed_outputs, h_n = gru(packed_batch, h_0)
print(packed_outputs)
print(packed_outputs[0].shape)
print(h_n.shape)
outputs, output_lens = pad_packed_sequence(packed_outputs)
print(outputs.shape) # (L, B, num_dirs*d_h)
print(output_lens)
# outputs: (max_len, batch_size, num_dir * hidden_size)
# h_n: (num_layers*num_dirs, batch_size, hidden_size)
Preprocessing for NMT Model
전처리된 src, trg 문장 반환
...
### 아래에 코드 빈칸(None)을 완성해주세요
src_sentence = []
tgt_sentence = []
# 기본형
for word in raw_src_sentence:
if word in src_word2idx: # src dictionary에 현재의 word가 있는 경우
src_sentence.append(src_word2idx[word])
else:
src_sentence.append(UNK) # src dictionary에 현재의 word가 없는 경우
for word in raw_tgt_sentence:
if word in tgt_word2idx: # tgt dictionary에 현재의 word가 있는 경우
tgt_sentence.append(tgt_word2idx[word])
else:
tgt_sentence.append(UNK) # tgt dictionary에 현재의 word가 없는 경우
# [선택] try, except을 활용해서 조금 더 빠르게 동작하는 코드를 작성해보세요.
for word in raw_src_sentence:
try:
src_sentence.append(src_word2idx[word]) # src dictionary에 현재의 word가 있는 경우
except KeyError:
src_sentence.append(UNK) # src dictionary에 현재의 word가 없는 경우
for word in raw_tgt_sentence:
try:
tgt_sentence.append(tgt_word2idx[word]) # tgt dictionary에 현재의 word가 있는 경우
except KeyError:
tgt_sentence.append(UNK) # tgt dictionary에 현재의 word가 없는 경우
# [선택] List Comprehension을 활용해서 짧은 코드를 작성해보세요. (~2 lines)
src_sentence = [src_word2idx[word] if word in src_word2idx else UNK for word in raw_src_sentence]
tgt_sentence = [tgt_word2idx[word] if word in tgt_word2idx else UNK for word in raw_tgt_sentence]
src_sentence = src_sentence[:max_len] # max_len까지의 sequence만
tgt_sentence = [SOS] + tgt_sentence[:max_len-2] + [EOS] # SOS, EOS token을 추가하고 max_len까지의 sequence만
### 코드 작성 완료
return src_sentence, tgt_sentence
Bucketing
- 길이가 비슷한 문장들을 묶어서 패딩을 줌 → 시간 효율 높임
### 아래에 코드 빈칸(None)을 완성해주세요
batch_map = defaultdict(list)
batch_indices_list = []
src_len_min = min(sentence_length, key=len)[0] # 첫번째 인덱스인 src의 min length
tgt_len_min = min(sentence_length, key=len)[1] # 두번째 인덱스인 tgt의 min length
for idx, (src_len, tgt_len) in enumerate(sentence_length):
src = (src_len - src_len_min + 1) // (max_pad_len) # max_pad_len 단위로 묶어주기 위한 몫 (그림에서는 5)
tgt = (tgt_len - tgt_len_min + 1) // (max_pad_len) # max_pad_len 단위로 묶어주기 위한 몫 (그림에서는 5)
batch_map[(src, tgt)].append(idx)
for key, value in batch_map.items():
batch_indices_list += [value[i: i+batch_size] for i in range(0, len(value), batch_size)]
### 코드 작성 완료
# Don't forget shuffling batches because length of each batch could be biased
random.shuffle(batch_indices_list)
return batch_indices_list
Collate Function
- 주어진 데이터셋을 원하는 형태의 batch 로 가공하는 함수
- batch 단위별로 max seqence length 에 맞게 pad 추가하고 내림차순 정렬
PAD = Language.PAD_TOKEN_IDX
batch_size = len(batched_samples)
### 아래에 코드 빈칸을 완성해주세요
batched_samples = sorted(batched_samples, key=lambda x : x[0], reverse=True) # 0번째 요소의 길이를 기준으로 내림차순 정렬
src_sentences = []
tgt_sentences = []
for src_sentence, tgt_sentence in batched_samples:
src_sentences.append(torch.tensor(src_sentence))
tgt_sentences.append(torch.tensor(tgt_sentence))
src_sentences = torch.nn.utils.rnn.pad_sequence(src_sentences, batch_first=True) # batch x longest seuqence 순으로 정렬 (링크 참고)
tgt_sentences = torch.nn.utils.rnn.pad_sequence(tgt_sentences, batch_first=True) # batch x longest seuqence 순으로 정렬 (링크 참고)
# 링크: https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_sequence.html
### 코드 작성 완료
assert src_sentences.shape[0] == batch_size and tgt_sentences.shape[0] == batch_size
assert src_sentences.dtype == torch.long and tgt_sentences.dtype == torch.long
return src_sentences, tgt_sentences
피어 세션
수업 질문
- [히스] Word2Vector 의 목적
- [히스] LSTM과 GRU 는 백프로파게이션을 셀 스테이트에 대해서만 하나요?
- [펭귄] 양방향 RNN/LSTM은 어떤 식으로 학습을 하나요?
Today I Felt
온라인 커뮤니케이션
나름 커뮤니케이션을 잘한다고 생각하며 살아왔는데, 온라인에서는 서로 서로 말할 타이밍을 잡아야하고, 얼굴로 감정을 보지 않고 소리가 주가 되다보니 오프라인 커뮤니케이션보다 힘든 점이 있다. 앞으로 온라인 커뮤니케이션이 더 활발해질지도 모르는 세상이기에 조금 더 온라인 커뮤니케이션에 맞는 역량을 키울 필요성을 느꼈다.
어제 클럽하우스에서 성킴님을 비롯한 여러 자연어 처리 전문가들이 GPT-3 에 대해 토론을 했다. 토론 내용도 너무 좋았지만, 온라인 커뮤니케이션 관점에서 성킴님의 모더레이터 역할에서 배울 점을 발견할 수 있었다. 본인이 말하기보다는 적절히 다른 사람들이 말할 기회를 열어주고, 전체 흐름 환기, 조율 등이 그것이다.
앞으로 피어 세션을 기회 삼아 조금 더 온라인 커뮤니케이션 능력을 길러야겠다 :)