목차
Intro to NLP, Bag-of-Words
이번 주 강의 목표
- NLU (Natural Language Understanding), NLG(Natural Language Generation) 이해
- NLP 와 관련된 여러 태스크 (NMT, QA 등) 이해 및 수행
Academic Disciplines related to NLP
NLP (major conferences: ACL, EMNLP, NAACL)
- State-of-the-art model 사용
- Low-level parsing
- 단어를 의미 단위로 준비하기 위한 단계
- Tokenization
- 단어를 token 이라 부르고, 주어진 문장을 단어 단위로 쪼개는 과정은 tokenization
- Stemming
- 한 단어의 어미 변화를 컴퓨터가 이해하도록 함 (좋다, 좋은데, 좋고 등)
- Word and phrase level
- 단어에 대한 분석 단계
- NER (Named Entity Recognition)
- New York Times 와 같은 단어를 하나로 인식
- POS (Part-of-speech) tagging, noun-phrase chunking, dependency parsing, coreference resolution
- Sentence level
- 문장 분석 단계
- Sentiment analysis
- 문장을 보고 긍정, 부정 구분 (It’s not bad → 긍정)
- Machine translation
- 주어진 영어 문장을 한글 문장으로 번역할 때, 문장 이해 및 어순 분석하여 번역
- Multi-sentence and paragraph level
- 다수의 문장 및 문단 분석
- Entailment prediction
- 두 문장간의 논리적 모순 분석
- Question Answering
- 독해 기반 질의 응답 (구글에 질문을 하면 예전에는 해당 키워드 문서 나열했다면, 이제는 답을 내놓음)
- Dialog systems
- 챗봇같은 대화 수행 시스템
- Summarization
- 문서 요약
Text Mining (major conferences: KDD, The WebConf (formerly, WWW), WSDM, CIKM, ICWSM)
- 빅데이터 분석과 관련 깊음, 1 년 동안 생긴 모든 뉴스 기사에서 키워드를 시간순으로 분석하여 인사이트 제공
- Document clustering (e.g., topic modeling)
- 관련된 문서 군집화
- 컴퓨테이셔널 사회 과학과도 관련
- SNS 에 많이 사용되는 신조어 분석하여 사회적 인사이트 생성
Information Retrieval (major conferences: SIGIR, WSDM, CIKM, RecSys)
- 구글이나 네이버 등에서 사용되는 정보 검색 기술
- 이미 충분히 발전하여 발전이 더딤
- 추천 시스템은 활발한 연구 중
Trends of NLP
- 이번 수업은 NLP 를 다룸
- CV (이미지 분야) 는 GAN 등 활용하여 빠르게 발전했으나, NLP 분야는 더디게 발전했음
- Word Embedding, 여러 차원을 지닌 단어를 점으로 표현 (Word2Vec)
- 과거에는 RNN 기반 모델이 기본이 되었음
- 요즘엔 Attention 과 Transformer 기반 모델이 기본
- 룰 기반 방식 (주어 목적어 보어 등) 은 번역 성능이 낮았음, 어텐션은 단어 간의 관계를 분석하므로 성능이 매우 뛰어남
- Transformer 모델은 NMT 외에 CV, 시계열 예측, 신약 개발 등 다양한 분야에 사용됨
- 발전된 Transformer 모델 (e.g., BERT, GPT-3)
- 단어 관계 분석은 방대한 데이터로 지도학습하고, 전이 학습으로 자가 지도 학습, self-supervised training (데이터에 라벨 없음 → 문장에서 몇 단어를 가려서 앞 뒤 문맥으로 유추하도록 학습) 을 학습하여 성능 향상
- 이러한 모델들은 엄청난 cost 가 있기 때문에 학습하기 어려움 (OpenAI 에서 만든 GPT-3 학습하는데 전기세만 몇 억원)
Bag-of-Words
- 1 단계 : 문장에서 유니크한 단어들만 vocabulary 에 모음
- 문장 : “John really really loves this movie”, “Jane really likes this song”
- Voca : {“John”, “really”, “loves”, “this”, “movie”, “Jane”, “likes”, “song”}
- 2 단계 : 사전의 단어들을 one-hot vector 로 인코딩
- 예시
- John : [1 0 0 0 0 0 0 0]
- …
- song: [0 0 0 0 0 0 0 1]
- 두 단어 사이의 거리는 $\sqrt{2}$
- 두 단어 사이의 cosine similarity (유사도) 는 0 (두 단어 관계 없음)
- 예시
- 3 단계 : 단어의 one-hot vectors 를 더하여 bag-of-words 생성
- “John really really loves this movie” → [1, 2, 1, 1, 1, 0, 0, 0]
NaiveBayes Classifier 를 활용한 문서 분류기



-
한계 : 어떤 단어가 아무리 다른 단어들과 관계가 많더라도 학습 데이터에 없는 단어면 이 단어가 나올 확률은 0 이 되어 분류 성능이 저하된다.
→ 스무딩 사용
Word Embedding
학습 방향
- Word2Vec 과 GloVe 가 단어를 학습하는 원리 이해
Further Reading
Further Questions
- Word2Vec과 GloVe 알고리즘이 가지고 있는 단점은 무엇일까요?
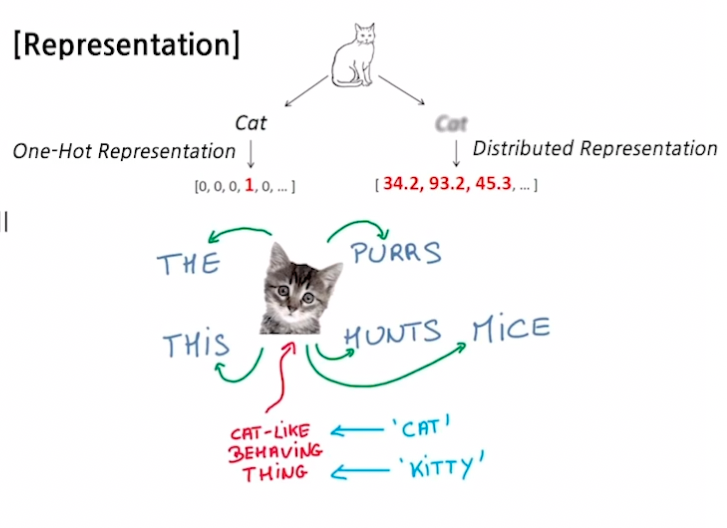
Word Embedding 이란?
- 단어를 벡터 (점) 로 표현
- ‘cat’ 과 ‘kitty’ 는 유사하기 때문에 벡터가 비슷해야 함 → 거리가 가까워야 함
- ‘hamburger’ 는 위 단어들과 유사하지 않으므로 벡터가 달라야 함 → 거리가 멀어져야 함
Word2Vec
-
가까운 단어들과 관계가 높다고 가정
- 1) 문장 내 단어 tokenization
- 2) 유니크한 단어로 사전 구축, 한 단어는 사전 사이즈만큼 크기를 가진 원 핫 벡터가 됨
- 3) sliding window 를 적용하여 한 단어를 중심으로 앞 뒤 단어들과 쌍을 구성함
- I study math → (I, study), (study, I), (study, math), (math, study)
-
입력 레이어의 차원과 출력 레이어의 차원은 같아야 함, 히든 레이어의 차원은 임의 설정 가능
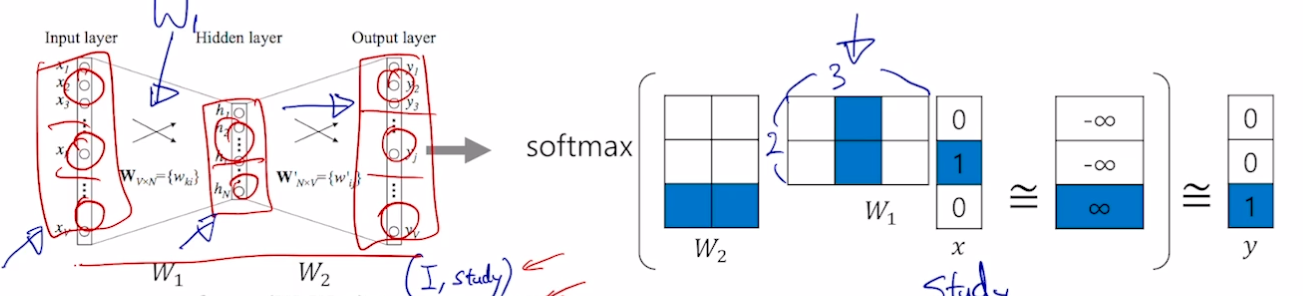
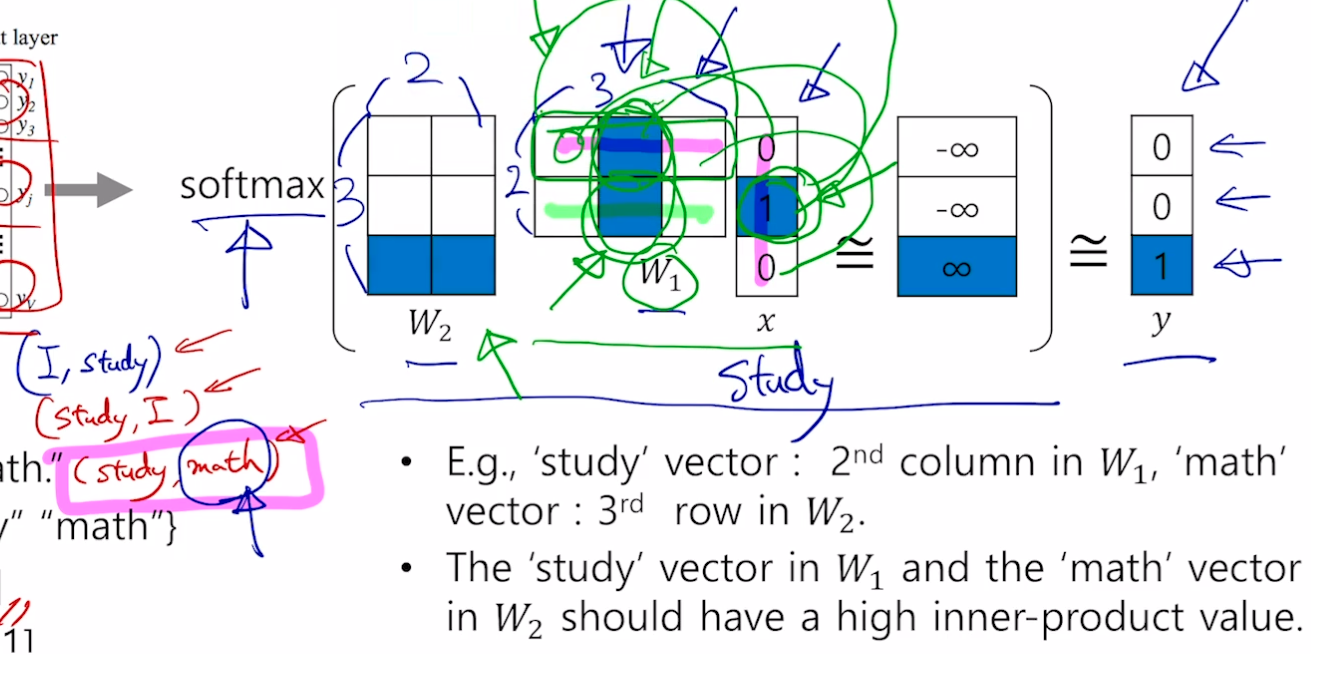
- (study, math) 예시
- 원 핫 벡터이기 때문에 W1 과 W2 의 해당 부분만 활성화됨
- 입력 [0, 1, 0] → [0, 0, 1] 이 됨
- 입력 단어와 출력 단어에 대해 W 가 최대가 되도록 함
-
Gradient Descent 를 통해 웨이트 학습
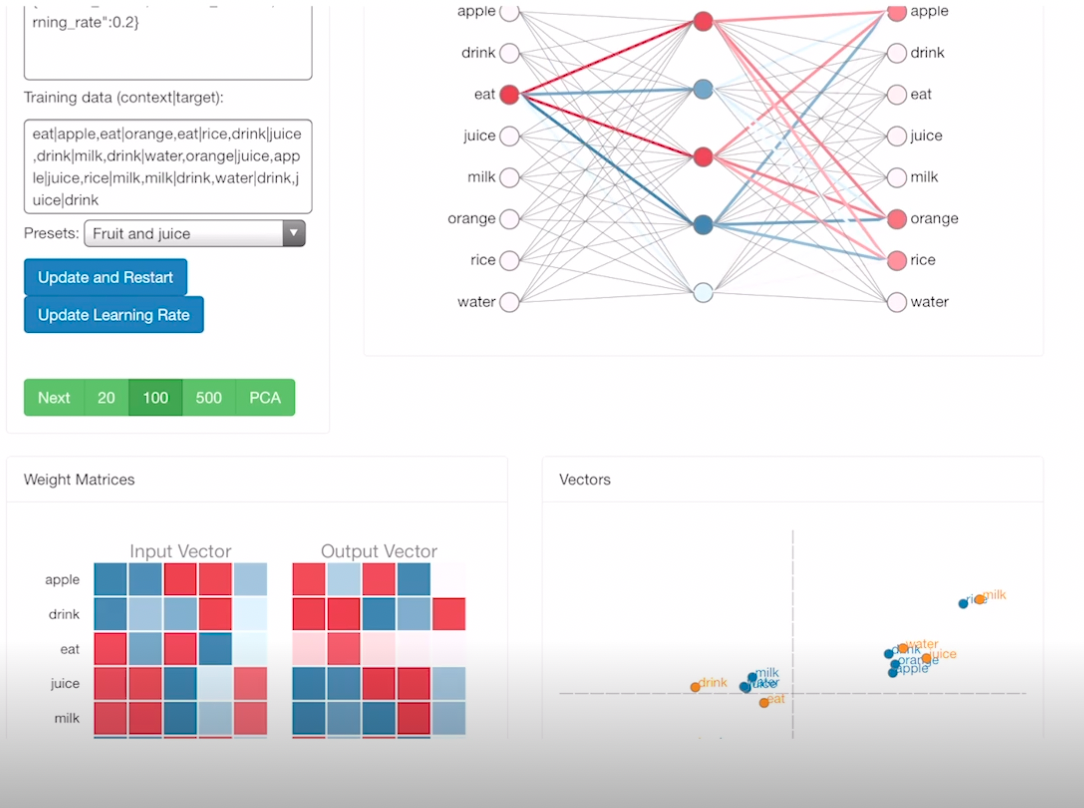
- 수렴된 모습
- 왼쪽의 W 매트릭스를 보면, 입력값 juice 에 대해 drink 가 유사함을 알 수 있음 (내적시 가장 값이 큼)
- 일반적으로 W1 (입력 임베딩 웨이트) 를 사용함
- 즉, 학습을 진행할 수록 입력, 출력 웨이트 매트릭스는 두 단어 사이의 관계 (유사도) 를 나타내줌
Property of Word2Vec
-
Analogy Reasoning
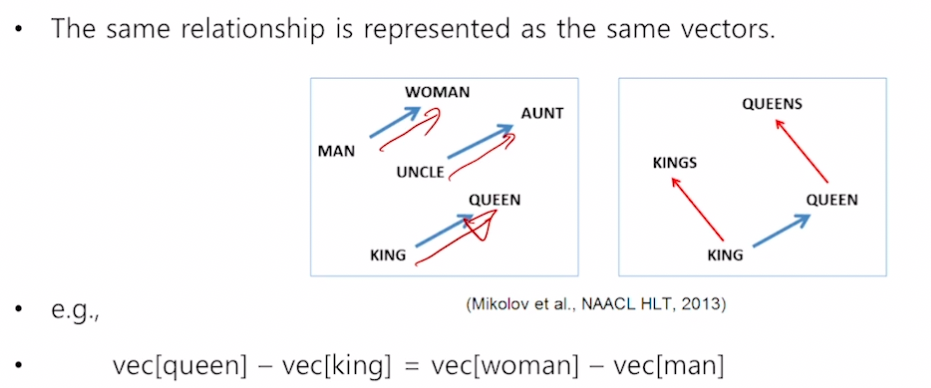
- 한국 - 서울 + 도쿄 = 일본
- Intrusion Detection
- 여러 단어가 주어졌을 때 나머지 단어와 가장 다른 단어 찾기
- 각 단어별로 word 벡터간의 유클리드 거리를 구해서 가장 먼 단어 찾으면 됨
- math, shopping, reading, science → shopping
- Word2Vec 은 NLP 문제들의 성능을 향상시킴
GloVe

- GloVe : Global Vectors for Word Representation
- Word2Vec 과 차이는 두 단어가 얼마나 등장했는지를 사전에 미리 계산하고, 두 단어의 내적 값이 두 단어 등장 횟수에 유사해지게 만들어 줌, 두 알고리즘 적용했을 때 성능 비슷
-
중복이 줄어들어 빠름
- 두 부류 간의 관계가 일정한 벡터로 나타남
*Word2Vec 과 GloVe 사이트 들어가면 이미 학습된 거 쓸 수 있음
Naive Bayes Classifier 구현
과정
1) 필요 패키지 import
- konlpy : 한국어 형태소 분석에 필요한 패키지
- tqdm : 상태 진행률 표시 패키지
- defaultdict : dict 기능 + 기본값 세팅 가능
2) 학습 및 테스트 데이터 전처리
- 한국어 레스토랑 리뷰 데이터를 이용, 적절한 감정 분류 목표 (0 : 부정, 1 : 긍정)
- knlpy.tag.Okt() 를 사용하여 주어진 문장을 토큰화 (단어 단위로 쪼개줌, 띄어쓰기 단위가 아니라 토크나이저가 자체적으로 판단하여 단어 위주로 쪼갬)
- 학습데이터 기준 가장 많이 등장한 단어부터 vocab 에 추가 → {단어 : 인덱스} 구조
3) 모델 Class 구현 (NaiveBayes Classifier)
- init
- k : smoothing 을 위한 상수
- w2i : 위에서 만든 vocab
- priors : 각 class 의 prior 확률
- likelihoods : 각 token 의 특정 class 조건 내에서의 likelihood
- train
- set_priors, set_likelihoods 진행
- inference
- 토큰이 들어오면 각 클래스별로 구해준 확률로 토큰에 대한 베이즈 확률 구해줌
- 조건부 확률 0~1 사이 값을 계속 곱해주면 0 으로 수렴할 위험이 있기 때문에 log 를 취해서 0 이 되지 않도록 함
- 클래스에 대해 구한 조건부 확률로 가장 큰 클래스 반환
- set_priors
- priors 계산
- set_likelihoods
- likelihoods 계산
- {token0 : {class0 : 확률, …, classN : 확률}, …, tokenN : {class0 : 확률, …, classN : 확률}}
- 확률 : 해당 토큰이 어떤 클래스에 등장한 횟수 + k / (전체 데이터에서 어떤 클래스가 등장한 횟수 + 전체 단어 개수*k) # 스무딩
- 스무딩을 왜할까?
- 이론에서 배웠던대로 트레인에 없는 likelihood 에 의해 테스트 값이 0 이 나오는 것을 막기 위해 사용
- 즉, 분자 분모가 0 이 되지 않게 하려고 사용
- Laplace Smoothing
- likelihoods 계산
4) 모델 학습
5) 테스트
Word2Vec 구현
과정
1) 필요 패키지 import
- 위와 동일 + Dataset, DataLoader 와 같은 torch 관련 패키지 추가
2) 데이터 전처리
- 학습 데이터는 동일하지만, 테스트는 문장이 아닌 단어로 진행 (단어간 관계 학습이므로)
- 토큰화 + w2i 사전 만듦
- 모델에 들어가기 위한 Dataset 클래스 정의 (딥러닝이므로)
- Word2Vec 모델은 CBOW (Continuous Bag of Words) 와 Skip-gram 두 가지 존재
- 두 모델 모두 윈도우 사이즈 세팅함
- CBOW 는 인풋으로 주변 단어들을 사용하고 아웃풋으로 중심 단어가 나옴. 주변 단어를 통해 중심 단어 예측
- 주변 단어의 원핫 벡터를 임베딩하고 이들을 더하여 레이어에 넣어 중심 단어 원핫 벡터가 나오도록 학습
- Skip-gram 은 중심 단어를 입력하여 주변 단어들을 출력으로 받음. 중심 단어로 주변 단어 예측
- 중심 단어 원핫 벡터를 임베딩하고 레이어를 거쳐 주변 단어들이 나오도록 학습
- CBOWDataset 데이터 클래스 (x : 주변 단어, y : 중심 단어) 와 SkipGramDataset (x : 중심 단어, y : 주변 단어, x 를 y 개수로 중복되게 설정하여 와 x 와 y 가 1대1 대응되게 함) 정의
3) 모델 Class 구현
- init
- embedding : vocab_size 크기의 one-hot vector 를 특정 크기의 dim 차원으로 embedding 시키는 layer
- linear : 변환된 embedding vector 를 다시 원래 vocab_size 로 바꾸는 layer
- forward
- CBOW : 주변 단어들을 임베딩하고 더한 후 리니어 진행
- SkipGram : 중심 단어와 주변 단어 1대1로 진행
4) 모델 학습
- hyperparameter (batch_size, lr 등) 세팅하고 dataloader 세팅
- CBOW 학습
- SkipGram 학습
5) 테스트
- 테스트 단어들을 w2i 를 통해 텐서로 만들고 이를 각 모델에 맞게 임베딩하여 해당 단어와 다른 단어들과 관계 파악
피어 세션
설 연휴
- 원딜 학습정리 하려했는데 안함
- 서폿 이사함, 코로나 검사ㅠㅠ
- 히스 부산가서 친구 집가서 놀다가 밤낮바뀜
- 엠제이 쉬었습니다
- 후미 밀린 게임
- 샐리 공부, 여행가서 떡갈비
- 펭귄 학습정리 밀린거 끝냈습니다
수업 질문
- [히스] GloVe 와 Word2Vec 의 차이가 무엇인가요?
- [펭귄] Distributional Hypothesis의 의미
- [MJ] 똑같은 단어가 있으면 Word2vec이 어떻게 동작하는지?
TED 세션 - 서폿님
심리학의 일반화와 관련된 오류에 대해 서폿님이 발표하였다.
Today I Felt
관성 만들기
일주일 간의 휴가로 규칙적이던 생활 습관이 무너지고 공부 관성이 줄어들었다. 다시 마음 다잡고 성장을 바라보며 몸을 만들어야겠다. 무엇보다 중간중간 집중력을 흐트러뜨리는 유혹들을 이겨내기 위해 [단기 목표-성취 전략] 을 잘 활용해야겠다.
심리학
오늘 TED 세션은 마치 대학 교양 수업을 듣는 것처럼 유익하고 재밌었다. 언론이나 주변 사람이 주장하는 데에 증거가 있는지부터 생각해야함을 느꼈다. 또한 평소에 바른 정보를 얻기 위한 노력해야함을 느꼈다.