목차
Generative Models
- What I can not create, I do not understand. - 리처드 파인만 -
Introduction
- generative model 을 배운다는 것은 어떤걸 의미할까?
- 그럴듯한 이미지나 문장을 만드는 것 이상
- 만들어내는게 전부가 아님
- 만약 강아지 이미지들이 주어진다면?
-
Generation : 만약 $x_\mathit{new} \sim p(x)$ 를 샘플링하면 $x_\mathit{new}$ 는 강아지처럼 보일 것임 (sampling)
→ implicit model
- Density estimation : p(x) 는 어떤 이미지가 주어졌을 때, 강아지같은지 고양이같은지 구분, 즉 만들어내는거 이상으로 감지 까지 가능함 (anomaly detection) → 이렇게 확률까지 얻어내는 모델을 explicit 모델이라 함
- Unsupervised representation learning : 여러 이미지들이 귀, 꼬리들과 같은 공통점이 있다는 것을 우리는 학습할 수 있음 (feature learning)
-
- p(x) 를 어떻게 만들까?
기본 이항 분포
-
베르누이 분포 : 동전 던지기
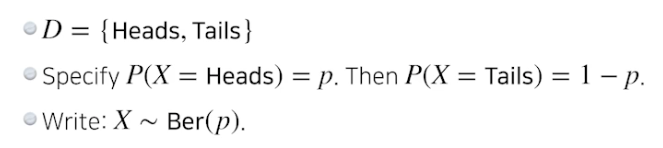
-
카테고리컬 분포 : m 면체 주사위 던지기
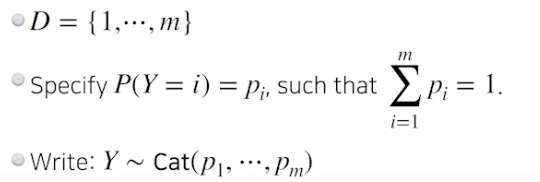
- RGB joint distribution (결합 분포) 을 모델링한다면
- (r, g, b) ~ p(R, G, B)
- Number of cases? → 256 x 256 x 256
- 파라미터 숫자가 얼마나 필요한가? → 255 x 255 x 255 (너무 많음) ⇒ fully dependent 는 너무 많은 파라미터 필요
- 흑백 이미지 N 개 X1, …, XN 이 있다면
- 경우의 수 → 2 x 2 … x 2 = $2^n$
- p(x1, …, xn) 의 파라미터 수는 → n
- $2^n$ 엔트리는 n 으로 설명 가능함. 하지만 이 독립 추정은 모델이 사용할만한 분포로서는 너무 강함
- 각각의 픽셀에 대해 파라미터 1 개 필요. n 개가 모두 독립적이므로 다 더하면 n 개.
⇒ fully independent 는 파라미터는 적지만 말이 안되는 추정
(Q. 지수가 배수되는 과정 더 알아봐야 함 → 독립이면 다 따로 각각 생각해서 변수 개수는 n 개, 다 더하면됨)
- Conditional Independence
- 위 두 개의 중간 : 체인 룰과 컨디셔널을 이용해서
-
세 가지 기본적인 룰

- 체인룰을 사용하면, joint 분포를 conditional 분포로 바꿔줌
- 어떤 것도 바뀌지 않음 → fully dependent 모델 파라미터 수와 같음
- 파라미터 수
- p(x1) : 1 param
- p(x2 | x1) : 2 params (one per p(x2 | x1 = 0) and one per p(x2 | x1 = 1))
- p(x3 | x1, x2) : 4 params
- $2^n-1$ 를 따름
-
Markov assumtion, 바로 전 입력에 의해 현재 입력 영향
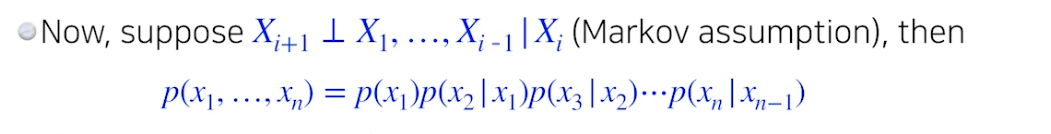
- 파라미터 수 : 2n - 1
- Markov asuumtion 모델을 레버리징하여 파라미터에 대해 exponential reduction (지수를 배수로 줄임) 가능
- Auto-regressive models 는 이 conditional independency 를 레버리징함.
Auto-regressive Model
- MNIST 이미지 28x28 짜리 숫자 사진이 있다고 가정하자.
- 우리의 목표는 p(x) = p(x1, …, p784) 를 학습하는것, x 는 0 or 1
- 어떻게 p(x) 를 파라미터화 할까?
- joint distribution 에 체인룰 적용
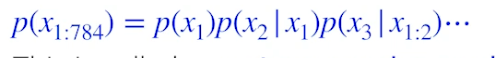
⇒ auto-regressive model
- 자기 회귀 모델은 하나의 정보가 이전 정보들에 의존적인 것
- 마코비언처럼 하나의 정보가 이전 정보에만 의존해도 (AROne 모델)
- 하나의 정보가 모든 이전 정보에 의존 (ARN 모델)
- 어떤 이미지를 자기회귀 하려면 랜덤 변수들에 대해 ordering (순서 매기기) 필요함
- 순서 매기는 방법에 따라 성능이 달라질 수 있음 (지그재그, 연속 등)
- joint distribution 에 대해 마코비언 추정을 하거나 다른 conditional independence 추정을 하는 것이 체인룰 입장에서 joint distribution 을 쪼개는 데에 어떤 관계가 있는지 생각할 것
NADE : Neural Autoregressive Density Estimator
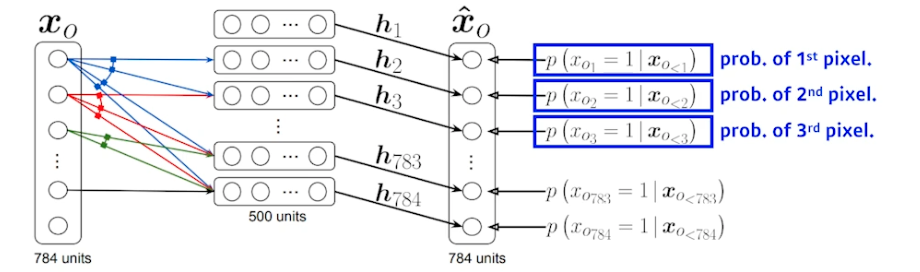
- i 번째 픽셀을 1 ~ i-1 번째 픽셀에 의존하게 만듦
- 첫 번째 픽셀의 확률분포는 독립적으로 만들고, 두 번째 픽셀의 확률은 첫 번째 픽셀에 의존 (h 가 됨), 세 번째 픽셀의 확률은 첫 번째와 두번째에 의존 … 끝까지 진행
- 100번째 뉴럴 네트워크 (100번째 픽셀에 대한 확률분포) 만들 때는 99 개의 이전 입력들을 받을 수 있는 뉴럴 네트워크 필요
- NADE 는 explicit 모델 (생성 + 확률계산) → 주어진 입력에 대해 density 계산 가능
-
784 개의 바이너리 픽셀 {x1, …, x784} 이 있다면, joint 확률은 아래와 같음

- 연속 확률 변수일 때는 마지막 모델에 가우시안 믹스쳐 모델을 사용
Pixel RNN
- auto-regressive model 정의하는데 RNN 사용 가능
-
n x n RGB 이미지가 있을 때, R 먼저 만들고 G 만들고 B 만듦
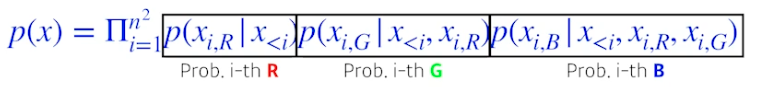
-
ordering 을 어떻게 하냐에 따라 두 버전 존재
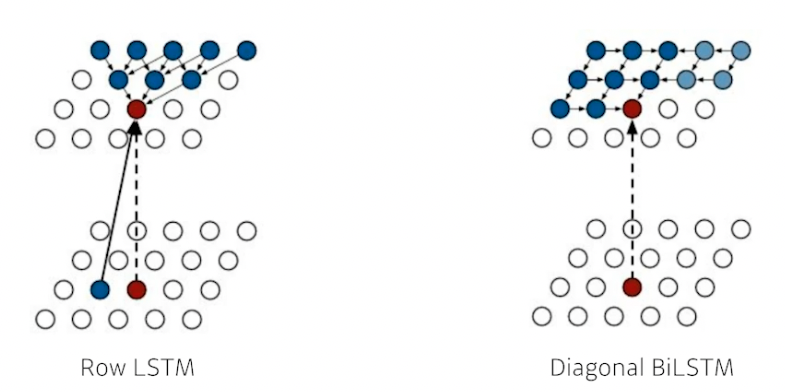
- Row LSTM : i 번째 픽셀을 만들 때 위쪽 정보 사용 (아래로 진행, 맞나?)
- Diagonal BiLSTM : bidirectional 하면서 자기 이전 정보 모두 사용 (옆으로 진행)
Latent Variable Models
- Kingma 박사가 만듦 (Adam 도 만듦, 박사 논문 읽어보는거 추천)
- Auto-encoder 도 generative model 일까? 사실 그렇지 않음, Variational Auto-encoder 가 일반 Auto-encoder 와 어떤 차이가 있고 어떻게 Variational Auto-encoder 는 generative model 되는지 알 것
Variational Auto-encoder
- Variational inference (VI)
- VI 의 목적은 variational distribution 을 posterior dist 와 최적의 매치가 되도록 최적화하는 것
- Posterior dist : $p_\theta(z|x)$
- 관측이 주어졌을 때 관심있는 확률 변수의 확률 분포
- 계산하기 힘듦 → 근사하는게 vd
- Variational dist : $q_\varnothing(z|x)$
- 가장 관심있는 pd 를 근사한 것
- Posterior dist : $p_\theta(z|x)$
- KL 발산을 사용해서 true posterior 를 최소화하는 vd 찾고자 함
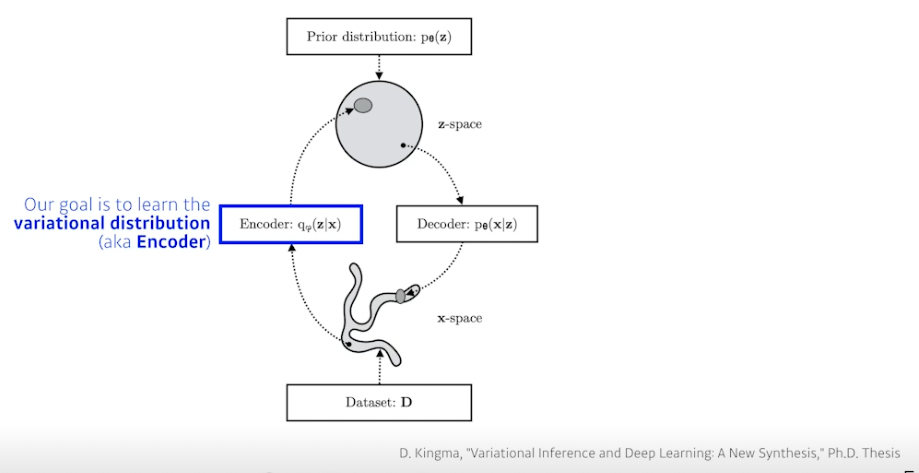
- VD 를 찾는게 목적 (Encoder)
-
문제는 posterior 를 모르는데 어떻게 이를 근사하는 VD 를 만들 수 있을까?
→ ELBO 트릭 사용
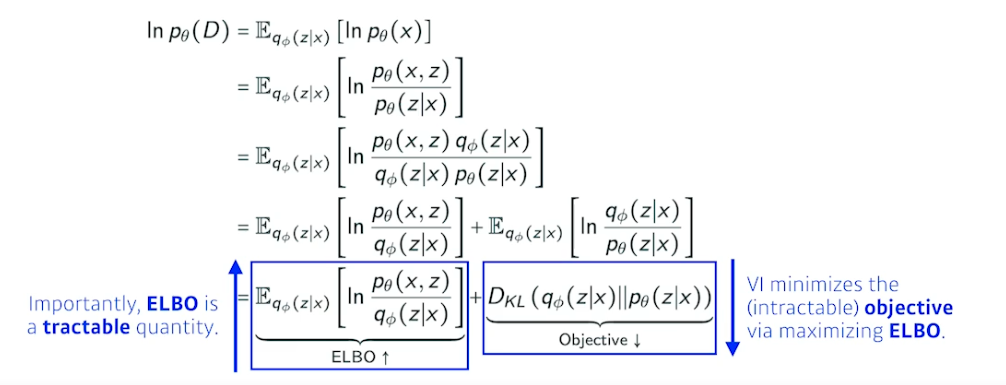
- ELBO (Evidence Lower Bound) 를 키움으로써 거리를 줄여줌
- 수식 따라가보는거 추천
-
ELBO
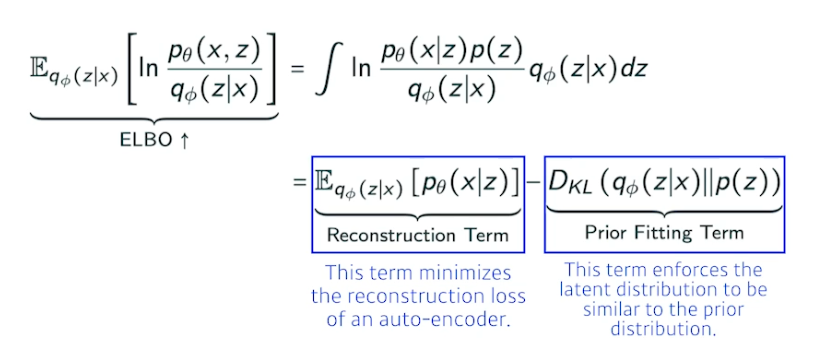
- Reconstruction Term : 인코더를 통해 x 라는 입력을 latent space 로 보냈다가 디코더로 돌아오는 Reconstruction loss 를 줄이는 것
- Prior Fitting Term : x 라는 이미지들을 latent space 에 올림 (점들). 점들이 이루는 분포가 내가 가정하는 latent space 의 prior dist (사전 분포) 와 동시에 만족하는 것과 같음
- 엄밀한 의미에서 Implicit model
⇒ 어떤 입력을 latent space 로 보내서 무언가를 찾고 이를 다시 reconstruction 하는 term 만들어지고, generative model 이 되기 위해서는 latent space 된 prior dist 로 z 를 샘플링 하고 디코더를 태워서 나온 아웃풋 (이미지) 를 제너레이션 result 로 봄.
- 일반 auto encoder 는 인풋이 latent space 갔다가 output 나오므로 generation model 아님
- Key Limitation
- intractable 모델 (가능성 측정이 힘들다)
- VA 는 Explicit 모델이 아님, 어떤 입력이 주어졌을 때 얘가 얼마나 비슷한지 (likeli 한지) 알기 어려움
- prior fitting term 은 반드시 미분가능, 따라서 diverse latent prior dist 사용하기 힘듦
-
일반적으로 isotropic 가우시안 사용 (모든 아웃풋 차원이 독립)
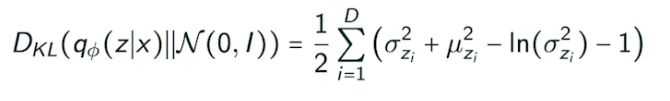
- 어떤 prior dist 가 가우시안이면, variation dist 와 prior dist 사이의 KL 발산은 위와 같이 close form 으로 나옴
- intractable 모델 (가능성 측정이 힘들다)
- 가장 큰 단점 : 인코더 활용할 때 prior fitting term 이 KL 발산을 활용하는 것, 가우시안 아닌 경우 활용 힘듦
- VI 의 목적은 variational distribution 을 posterior dist 와 최적의 매치가 되도록 최적화하는 것
Adversarial Auto-encoder, AAE
- Gan 을 활용해서 latent dist 사이의 분포를 맞춰줌
- Auto encoder 의 KL 발산에 있는 prior fitting term 을 GAN objective 로 바꾼 것
-
샘플링 가능한 latent dist 가 있으면 맞춰줄 수 있음 (uniform dist, 가우시안 믹스쳐 등) → 여러 분포 활용 가능하다는게 장점
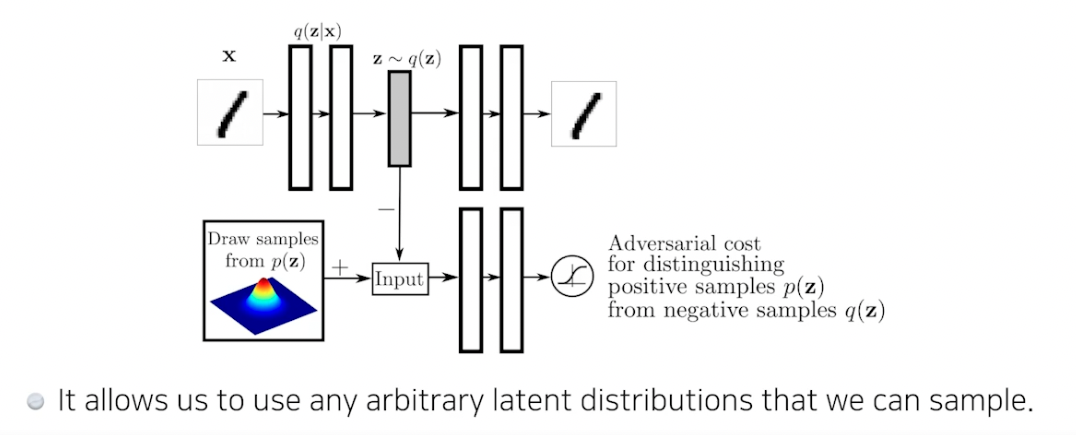
- 성능도 VA 보다 좋을 때가 많음
GAN
-
아이디어 : 도둑 (Generator) 이 위조지폐를 만드는데 이를 잘 분별하는 경찰 (Discriminator) 이 있다. 도둑은 분별된 돈으로 더 진짜같이 만들려하고, 경찰은 위조와 진짜지폐를 봐서 더 잘 구분하려함
→ 반복함으로써 generator 성능을 높임
- two-player game
- 한 쪽은 높이고 싶어하고, 한 쪽은 낮추고 싶어함
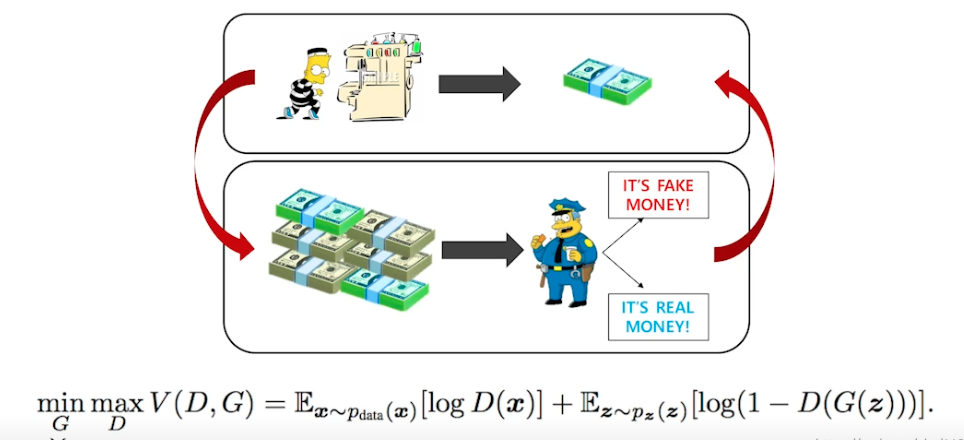
- 장점 : discriminator 가 성능이 좋아짐에 따라 generator 가 좋아진다.
-
Implicit model
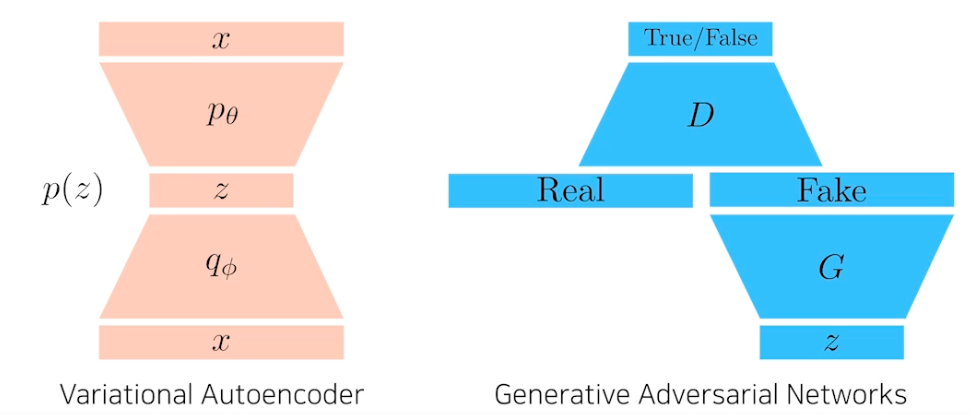
- z 로 출발해서 제너레이터 통과해서 가짜 만들고 디스크리미네이터는 가짜와 진짜를 보고 판단
-
Discriminator
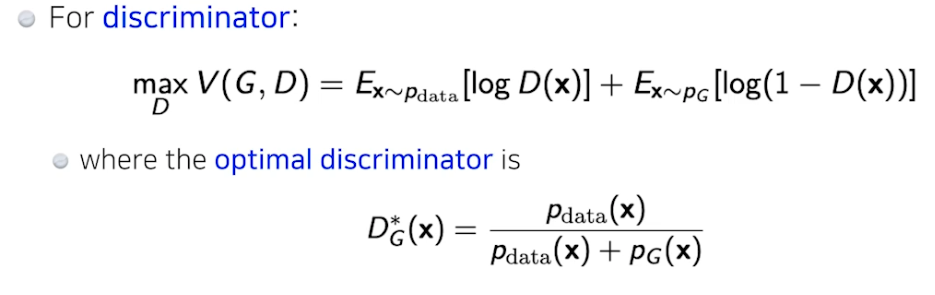
- Generator
- optimal discriminator 를 집어넣음

- 엄밀히 말하면 dis 가 optimal 이라고 가정했을 때, 이를 gen 이 학습하면 위와 같은 식이 나왔는데 실제로는 dis 가 optimal 수렴하는거 보장 힘듦 → gen 식 보장 안됨 (이론적으로는 가능하지만)
- AAE 에 활용
DCGAN
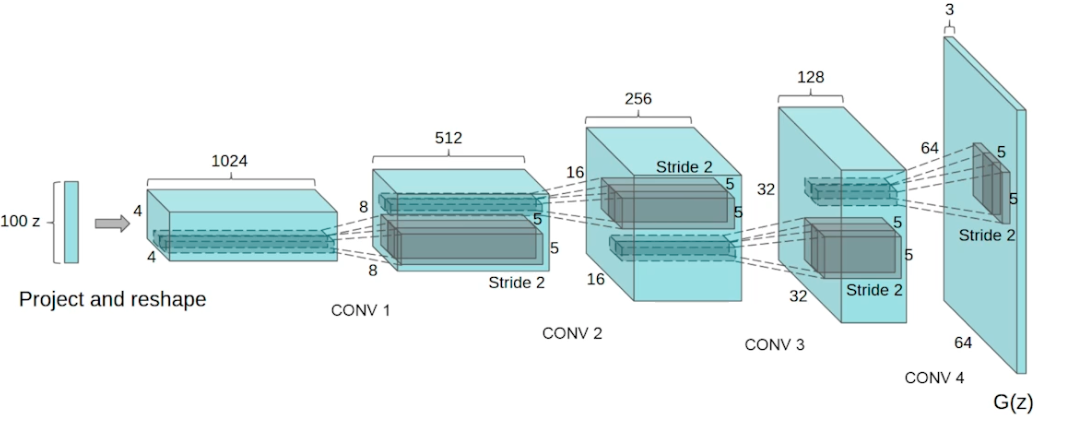
- 기본 GAN 은 MLP, 얘는 이미지에 사용
- LeakyReLU 사용
- 이미지 만들 때 좋은 하이퍼파라미터 사용
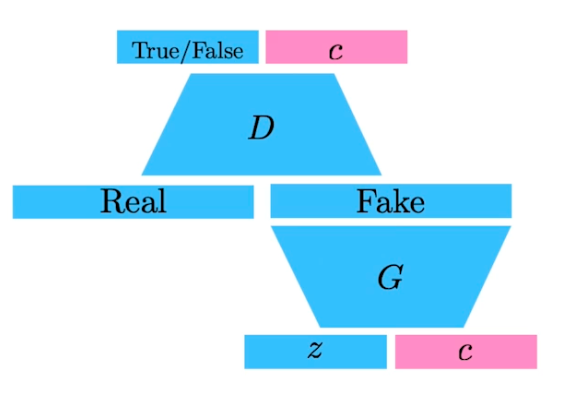
Info-GAN
- 학습할 때 단순히 z 로만 만드는게 아니라 class c 를 사용해 만들자.
Text2Image
- 문장을 사진으로 바꿈
- DALL-E 의 조상
Puzzle-GAN
- 이미지 안에 서브패치 (헤드라이트, 바퀴 등) 들로 원래 이미지 복원하는데 사용
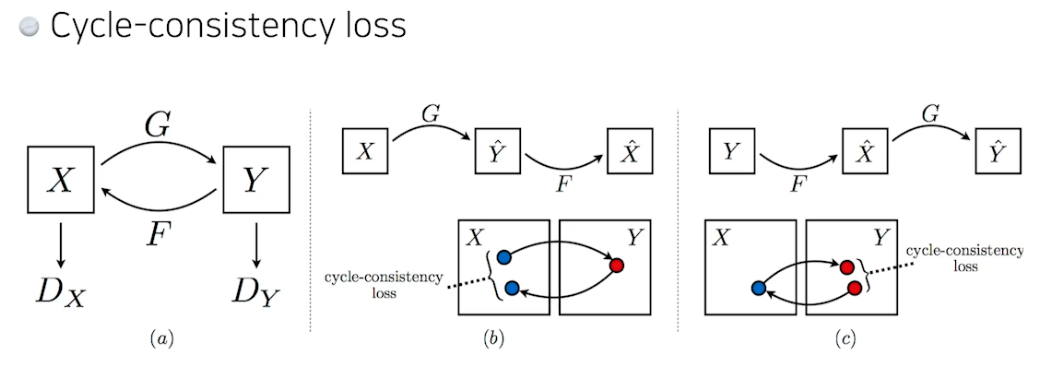
CycleGAN
- 이미지 사이 도메인 변경, 말→얼룩말 바꾸기
- Cycle-consistency loss 중요
Star-GAN
- 인풋을 어떤 필터에 따라 바꿔줌, 컨트롤 할 수 있게 해줌
- 네이버 작품
Progressive-GAN
- 센세이션한 성능
- 4x4 픽셀 → 8x8 → … → 1024x1024 로 늘려나가면서 학습
- 좋은 성능 이미지 만들어냄
Further Reading
마스터 클래스 - 최성준 교수님
1. 실제 실무에서도 CNN, RNN 을 활용하여 모델을 만드는지 아니면 밑바닥부터 모델을 구축하는지 궁금합니다.
: 파이토치나 텐서플로우 같은 API 당연히 씀. 연구에는 파이토치, 서비스는 텐서플로우 더 씀
2. 실습시간에 배운 코드들을 어느정도까지 익혀야 하는지 궁금합니다. 코드를 밑바닥부터 구현 가능한 정도까지 익히는 것이 시간이 오래걸리더라도 투자할만한가요?
: 연구에서는 밑바닥부터 하는게 좋고 실무에서는 툴 쓰면서 가독성 좋게 잘 쓰면 됨
3. 국내에서 석사, 박사를 하신 걸로 아는데 영어 공부는 어떻게 하셨나요? 회화나 쓰기 역량은 어떻게 쌓으셨는지 궁금합니다.
: 디즈니에서 일할 때 영어 쓸 수 박에 없는 환경
4. 논문을 보는 특별한 팁
: 이 논문을 내가 실험할거다 하면 실험 섹션을 많이 봄 (세팅, 알고리즘 등). 일반적으로는 인트로덕션 (이 연구를 왜하게 됐는지) 을 더 봄 (앞으로 어떤걸 할지도 알 수 있어서)
5. AI 엔지니어의 역량이 무엇이라 생각하시나요? 데이터 전처리 및 파이프라인 구축 역량, 모델 구현 및 서비스단까지 전달 역량 두가지 중 어떤 역량을 중점으로 가져가야 할까요?
: 잘 모르겠다. 카카오 브레인에서 일반적으로 뛰어난 AI 엔지니어는 둘 다 잘했음
6. RNN 이나 LSTM 같은 모델은 굉장히 복잡해 보이는데 이런 네트워크를 만들기 위한 intuition 은 어디서 얻을 수 있을까요?
: 잘 모르겠음. bio-inspired (실제 뇌 구조 영감) 된게 아닐까. 수업에서 말했듯 그럴 필요 없지만 새로운거 만들 때 참고하면 좋음
7. 모델을 그림으로 표현할 때 사용하는 툴
: 무식하게 키노트로 그림
8. 파라미터를 줄이면 일반화 성능이 오른다고 하셨는데, 실제로 많은 태스크에서는 파라미터를 줄이기보다 늘릴수록 성능이 올라가는 경우가 많은거 같습니다. 의견이 궁금합니다
: 원래 이론은 그랬는데 요즘엔 GPT-3, switch-Transformer 등 보면 파라미터 매우 많은데 성능이 올라감. 잘모르겠음. 많은 경우 일반화 성능은 평균보다 워스트 케이스 관점으로 보는듯. 요즘 트렌드는 바뀌고 있다~ 데이터셋이 많다면 무조건 모델 크기를 키우는게 맞지 않나 생각
9. 설명을 매우 잘하시는데 강의나 발표 준비할 때 팁이 있을까요?
: 생존을 위해 열심히 하고 있다. 패스트 캠퍼스에서 강의하면서 도움 많이 되었음. 많이 하면 느는듯. 주변에 똑똑한 사람들이 많은데 이들은 설명을 잘 못함 너무 똑똑해서. 천재가 아니라 더 잘 설명하는게 아닐까 싶다.
라이브 Q&A
회사에서 머신러닝 엔지니어 직무를 맡길 때 석사로 기대하는 것과 학사로 기대하는 것이 어떤 차이점이 있을까요?
: 회사마다 다른듯. 삼성같은 대기업이면 학사와 석사의 일이 달라짐. 스타트업이면 상관없이 그냥 잘해야함.
교수님 랩실에 들어가기 위한 지원자격이 궁금합니다
: 면담해봐야함. 열심히 하려하면 됨. 메일보내면 가능.
디즈니에서 리서쳐로 계실 때 구체적으로 어떤 업무를 하셨는지 간략하게 소개 부탁드립니다!
: 대외비. 말할 수 없음. 언론에 나온거로는 사전로봇 활용, 로봇 모션 만듦. 디즈니 리서치 조직은 디즈니 랜드와 월드에 들어가는 솔루션을 제공하는 곳
엔지니어와 연구자 사이에서 고민중인 대학생입니다. 대학원에 진학해 연구하고 싶은 마음도 있는데 수학이 어느정도로 중요할까요? 르벡적분이나 대학원 수준의 확률론도 중요할까요??
: 중요. 잘하면 좋음.
최신 연구 트렌드를 캐치하는 팁을 얻고 싶습니다. 단순히 논문을 많이 읽어서 트렌드를 잡기에는 매년 나오는 논문의 양도 많고 이들을 선택하는 데도 시간이 너무 많이 소요됩니다. ㅠㅠ
: 논문이 너무 많아서 쉽지 않은 문제. 제일 좋은 팁은 논문 많이 보는 사람 옆에 두면 됨. 찔러보면 자기들이 본 논문 추천해줌. 자기만의 연구 분야가 생기면 연구 트렌드는 덜 중요해짐.
왜 서빙을 할때는 tensorflow가 많이쓰이나요?
: 잘 모르지만 파이토치 쓰면 버그가 있다 하더라.
엔지니어를 목표로 하는 캠퍼입니다! 모르는게 너무 많기도 하고, 공부해야 할 양도 많아보여서 그런지, 요즘 대학원 진학에 대한 생각을 다시 해 보게 되었습니다. 교수님이 석사(혹은 박사)로 진학하게 된 계기가 궁금합니다!
: 학부 때, 군대 대신 청소로봇 만드는 회사에 있었음. 원래는 학사 마치고 스타트업 만들랬음. 학부 때 지식이 얼마나 미천한지 깨닫고 대학원 감.
self supervised learning(이하 ssl)이 뜰거라 하셨는데 회사에서 뉴스에 감성 score나 tag를 적어놓은 data를 비싸게 사오더라고요. ssl을 이용하면 사온 데이터를 이용해 score/tag 모델을 리버스 엔지니어링 할 수 있나요? 이런 모델의 한계는 뭘까요?
: ssl 컨셉 (라벨 없는 데이터를 활용해보자) 자체가 재밌음. 한계점은 라벨이 없으니 믿을 수 없을 수도 있다?
데이터 파이프라인이라는게 어떤 것인지 감이 안옵니다 .. dataloader를 말하는 건가요?
: 데이터 모으고 전처리하고 컴퓨터가 읽을 수 있게 하는 과정까지. 제일 중요한거는 전처리 과정 (실제 데이터는 노이즈가 많기 때문)
논문을 보실때 어떠한 기준으로 보는지 또 어떤 내용을 중점적으로 보는지 알려주세요(수식을 위주로, 결과를 위주로, 기술을 위주로 등)
: 수식은 어렵고 재미없어서 잘 안보려함. 인트로덕션을 많이 보려함. 이거 보면 기존 문제 (읽지 않은 논문도 알려줘서 좋음) 도 알 수 있음
교수님이 연구실에서 진행하고 계신 연구 분야가 궁금합니다!
: 로보틱스와 시뮬레이션, 모션. 로봇이 사람과 같이 사는 공간에 오면 움직이는게 필요하므로
슬럼프가 왔을 때 어떻게 극복하셨나요? 벽을 느꼈을 때나..?
: 지금도 슬럼프. 답없음. 잘모르겠음. 박사 때는 논문만 쓰면 좋았는데 요즘에는 주변에 잘하는 사람 너무 많아서 힘들어 페북에 글썼다가 멘토한테 징징대지 말라고 혼남.
기업에서 리서치를 하신다고 하셨는데, 리서치 결과를 실제 서비스에 반영하기 위해 엔지니어는 어떤 일을 하게 되나요? 리서쳐와 여러 커뮤니케이션 과정을 거쳐 모델을 개발하게 되는걸까요?
: 엔지니어가 다 함. 전처리부터 서빙까지 백엔드 프론트엔드 전부 다함. 커뮤니케이션 중요.
강의를 보면 논문이 나오고 기술이 바뀌는 시기가 엄청 빠른 것 같던데 AI엔지니어로 살려면 새 논문과 신기술을 항상 check해야 하나요? 아니면 실무에서 쓰는 모델이나 툴은 덜 민감한 편인지..
: 회사의 기술은 생각보다 쉽게 잘 안바뀜. 리서쳐는 매번 체크해야하지만 엔지니어는 좀 다름.
모델을 만들 때 먼저 수식적으로 연구하고 만드는지, 먼저 모델을 만들고 수식으로 증명하는지 궁금합니다.
: 수식 제대로 증명한 적 거의 없음 어려워서.. 이떄까지 1번 해 봄. 모델 만들때 수식 먼저 적고 코딩함. 증명 잘 안함 교수님은
리서치에는 파이토치를 많이 사용하고 실제 배포 시에는 텐서플로우를 많이 사용한다면 엔지니어로 취직하려면 텐서플로우를 배워야할까요??
: 엔지니어로 취업하려면 둘 다 할 줄 알아야할듯
석사와 박사
: 연구쪽으로 하고 싶으면 무조건 박사. 엔지니어 하고 싶으면 노상관, 실력이 중요. 대학원은 공부를 하는 곳.
다양한 분야 정보를 얻고 흥미 분야를 정하고 싶어요
: 학회 등에서 다양한 사람들 만나서 교류 도움됨. 온라인보다.
피어 세션
수업 질문
[히스] generative model 에서 generator 로 실제 아웃풋 생성
데이터셋 만들기
- 시간 : 2/9 14~17pm
- 주제 : 닮은 사람 분류 (아이즈원 김채원, 조유리, 최예나)
Today I Felt
설 연휴 = 메꾸는 시간
다음주는 통으로 휴강이다. 바로 오예를 외쳤지만 사실 그 시간은 모든 강의 복습 및 부족한 공부를 하는 시간이 될 것 같다. 그리고 실습으로는 notMNIST 데이터 클래스 만들기, 트랜스포머 코드 연구, 우리 조 데이터셋 만들기를 할 예정이다. 쉬기도 쉬겠지만 공부할 생각부터 하다니 대견스다. 사실 머신러닝 공부가 재밌다. 학교 시험용이 아니라 내가 알기 위해 공부하는거라 그런거겠지? 아무튼 설 연휴 다음부터 있을 본격적인 수업 전에 기본을 확실히 다져야지!