목차
Optimization
Introduction
- 최적화와 관련된 여러 용어들에 대해 명확히 알아야 함, 그러지 않으면 다른 사람들과 얘기할 때 어려움을 겪을 것
- Gradient Descent : 미분 가능한 함수에서 로컬 미니멈을 찾기 위해 일차 미분 최적화 알고리즘을 사용하는 방법
Important Concepts in Optimization
Generalization
- 많은 경우에 모델의 일반적인 성능을 높이는게 목적 → 일반적이란?
- 학습을 시킬 때 마다 Training error 는 내려감, 하지만 Test error 는 오히려 올라갈 때가 있음
- Generalization gap : Test error 와 Train error 의 차이 => Test 성능을 Training 때 만큼 보장해주는게 목적
- 그러나 근본적으로는 Training 성능이 좋아야 함
- Underfitting : 학습이 덜 돼서 트레이닝 예측도 잘 못하는 경우
- Overfitting : 학습이 너무 많이 돼서 학습데이터에 대해서는 잘 맞추지만 모델의 모양이 이상해져서 실제 예측을 잘 못하게 됨 (그러나 이렇게 구불구불한 모양을 원할 때도 있을 수 있다.)
Cross-validation
- 얼마나 모델이 독립적인 테스트 데이터셋에 일반화 잘하는지 평가하기 위한 모델 유효성 검증 테크닉
- Cross-validation : 예를 들어 학습 데이터가 10만개면 (테스트 데이터와 별도) 2만개씩 5 folds 로 나누고, 첫 번째 학습에서는 1~4 folds 를 학습에 쓰고 fold 5 를 validation 하고, 두 번째 학습에서는 1, 2, 3, 5 folds 를 학습에 쓰고 fold 4 를 validation 하는 식으로 진행
→ 학습 데이터를 k 개로 나누고 k-1 개 학습, 1 개 validation - 파라미터 : 내가 찾고 싶은 값, 웨이트 등
- 하이퍼 파라미터 : 미리 정해두는 값, lr, loss-function 등
→ 어떻게 세팅하는게 최적인지 모르니까 크로스 밸리데이션을 통해 최적의 하이퍼 파라미터셋을 찾음
→ 이 하이퍼 파라미터를 적용하고 이제는 모든 데이터로 학습 진행 - (중요) 테스트 데이터는 학습에서 절대 사용하면 안됨, 크로스 밸리데이션, 밸리데이션 등 어떤 경우에도 사용하면 치팅이라 안됨
Bias and Variance
- 총을 쏠 때 원점이 아니라도 탄착군이 형성되면 좋음 (variance 가 작은 모델임) → bias 만 옮기면 좋아지니까 ⇒ Low Variance (분산이 적음, 뭉쳐있음)
- Variance 가 큰 모델은 비슷한 입력이 들어와도 출력이 달라짐 → overfitting 될 확률이 높음
-
Bias 가 높으면 mean 을 잘 못찾고 있는것
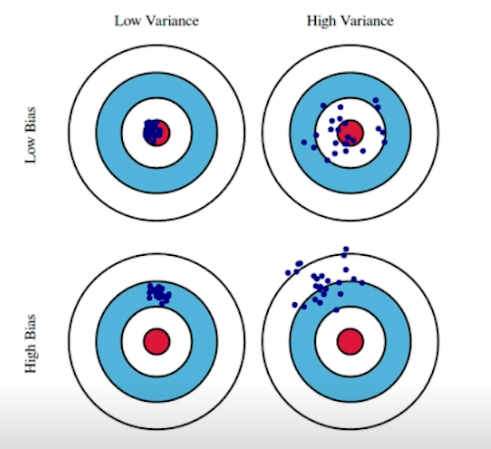
Bias and Variance Tradeoff
-
노이즈가 낀 학습데이터를 사용하여 로스를 최소화하는 과정은 사실 세 가지 값이 연관되어 있음
→ $bias^2$, variance, and noise
-
노이즈가 낀 데이터를 사용할 때는 bias 를 줄이면 variance 가 커지고, variance 를 줄이면 bias 가 커짐
Bootstrapping
- 신발끈을 위로들어 하늘을 날겠다!
- 랜덤 샘플링을 사용하여 성능을 높이고자 하는 방법
- 100 개의 학습데이터가 있으면 다 사용하지 않고 랜덤하게 80 개만 사용해서 모델을 만듦. 여러번 수행하여 만들어진 모델들은 같은 하나의 입력에 대해서도 같은 값을 예측할 수도 있지만 다른 값을 낼 수도 있음
→ 얼마나 모델들이 일치를 이루는지 체크
→ 전체적인 모델의 uncertain 을 확인 - 학습 데이터가 고정돼있을 때, 랜덤 샘플링하여 여러 모델을 만들어 측정하겠다!
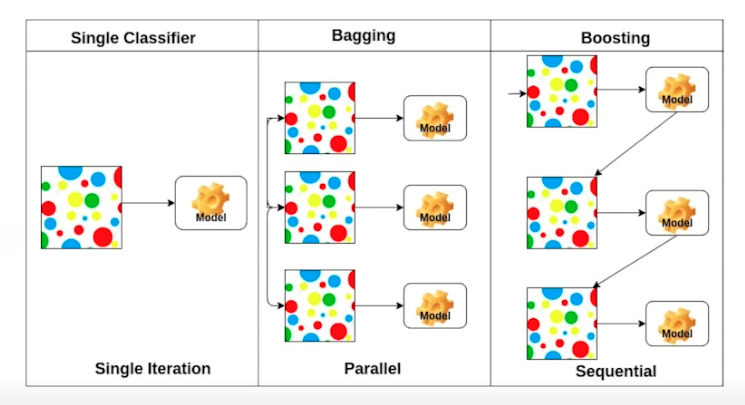
Bagging vs. Boosting
- Bagging (Boostrapping aggregating)
- 정해진 학습데이터를 모두 사용하여 1 개의 모델을 만드는게 아니라 학습데이터를 부트스트래핑해서 여러 모델 만듦
→ 모델들의 아웃풋을 평균냄 - 다른 말로 앙상블
- 하나의 모델보다 성능이 좋음
- 정해진 학습데이터를 모두 사용하여 1 개의 모델을 만드는게 아니라 학습데이터를 부트스트래핑해서 여러 모델 만듦
- Boosting
- 분류하기 어려운 학습 데이터가 있을 때 사용하기 용이함
- 일부 (잘 학습 안되는) 데이터로 모델 따로 만듦 (weak learners), 이렇게 weak learners 를 합쳐서 A strong model 을 만들어냄
- 합칠 때 sequential 하게 함 → 이전 weak learner 의 실수로부터 다음 weak learner 는 배워나감 ⇒ strong model 완성
Gradient Descent Methods
- Stochastic Gradient Descent
- 싱글 샘플 (전체에서 추출) 로부터 gradient 계산하고 경사하강법 수행
- Mini-batch Gradient Descent
- 한 데이터의 여러 서브셋 (전체를 여러개로 나눔) 으로부터 gradient 계산하고 경사하강법 수행 ⇒ 대부분 딥러닝에서 미니배치 사용
- Batch Gradient Descent
- 한 번에 전체 데이터 다써서 gradient 계산하고 경사하강법 수행
Batch-size Matters
- 미니배치에서 배치사이즈를 어떻게 정하는가
-
큰 배치사이즈를 사용하면 sharp minimizer 에 도달하고, 작은 배치사이즈를 사용하면 flat minimizer 에 도달 → flat minimizer 가 좋음 → 작은 배치 사이즈가 좋음
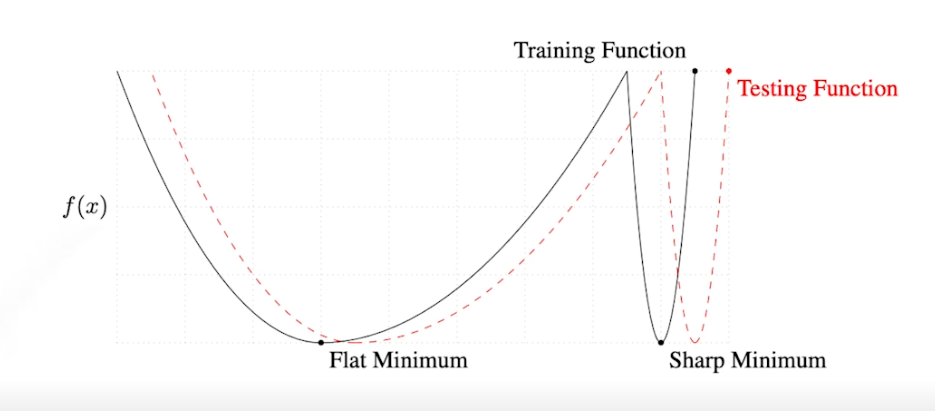
- flat minimizer 는 general 이 잘 됨, 플랫해야 범위가 넓어서 테스팅과 트레이닝의 갭이 작으니까
Gradient Descent Methods (자동미분 계산 방법들)
(Stochastic) Gradient Descent
- $W_\mathit{t+1}\ ←\ W_t\ -\ \eta g_t$
- 문제점 : 러닝레이트 $\eta$ 를 잘 잡는게 어려움
Momentum
- 더 빨리 학습시켜주기 위한 방법, 관성
-
한 번 한 방향으로 진행됐으면 다음에도 그 방향으로 진행될 가능성이 높음
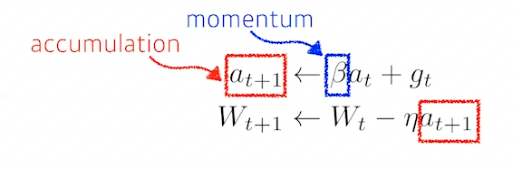
- accumulation 을 사용하여 그 방향으로 계속 흘러가게 해줌, 방향을 어느정도 유지시켜줌
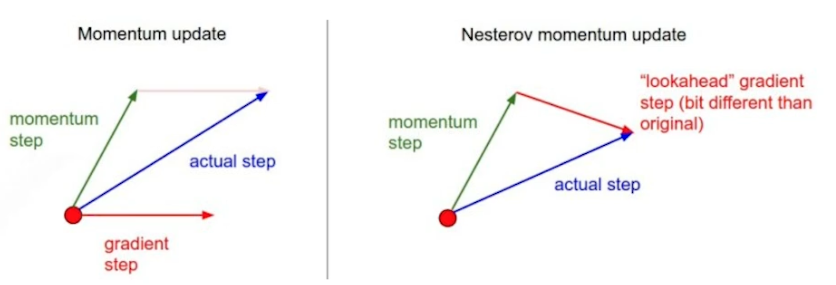
Nesterov Accelerated Gradient, NAG
-
Momentum 과 비슷하지만 Lookahead gradient 를 사용, a 라는 현재 정보가 있으면 그 방향으로 한 번 가보고 그 간곳에서 gradient 를 계산하여 축적함
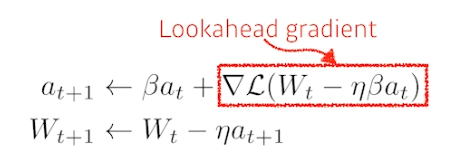
-
모멘텀은 로컬 미니멈에 수렴못하고 왔다갔다 하는 경우가 있는데 이를 고친 방법, 한 번 지나간 그 점에서 grad 를 계산하므로 수렴 가능
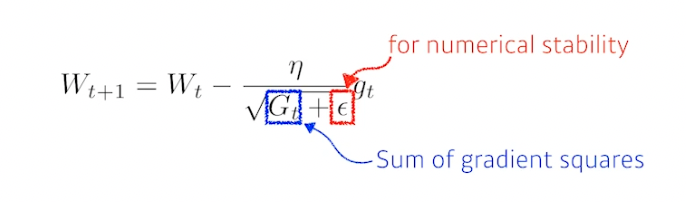
Adagrad
- Ada : Adaptive
- 뉴럴 네트워크의 파라미터가 지금까지 많이 변한 파라미터는 적게 변화시키고, 적게 변한 파라미터는 많이 변화시킴
- 지금까지 얼마나 파라미터들이 변했는지를 G 에 저장. 역수에 넣기 때문에 위의 설명대로 진행됨
-
문제 : 시간이 지날수록 G 가 결국 계속 커지기 때문에 업데이트가 너무 적어짐
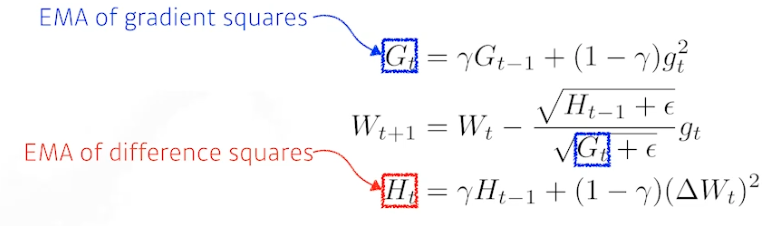
Adadelta
- Adagrad 에서 G 가 계속 커지는 현상 막음
- EMA : 지수 이동 평균 (Exponential Moving Average)
- 오래된 자료에 대한 가중치가 기하 급수적으로 감소
-
러닝레이트가 없음 → 바꿀 수 있는 요소가 별로 없음 → 잘 사용 안 함
RMSprop
- 논문을 통해 제안된건 아니고 제프 힌튼이 강의 중에 제안한 방법, 따라 해보니 잘됐음
-
Adadelta 에 lr (step size) 를 넣음
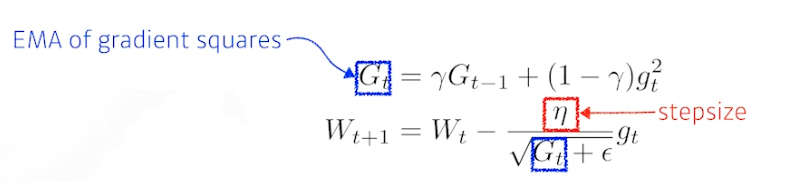
ADAM
- 일반적으로 사용됨
- Adaptive Moment Estimation, 과거 grad 와 제곱 grad 를 함께 지님
-
모멘텀과 adaptive learning rate 를 합친 방법
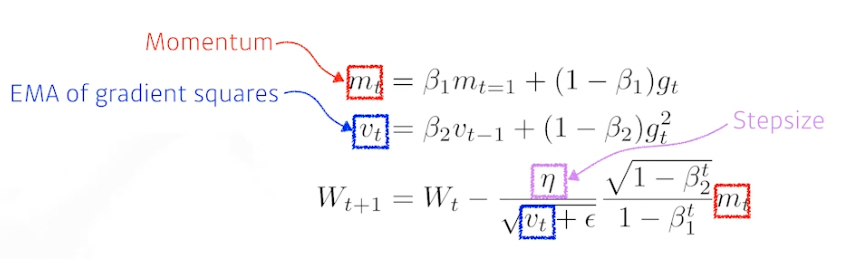
(optimizer 들을 직접 구현할 필요는 없고 제공하는거 한 줄 쓰면 됨)
Regularization
- 학습을 방해해서 학습데이터에서만 잘 동작하는게 아니라 테스트 데이터에서도 잘 동작하게 해주는 방법들
Early stopping
- 너무 많은 트레이닝을 하면 오버피팅돼서 test 와 성능 차이가 심해지므로 적절한 지점에서 학습을 멈춤
- test error 는 사용할 수 없으므로 (치팅) validation error 를 통해 멈추는 지점을 찾음
Parameter Norm Penalty
- 뉴럴네트워크 파라미터가 너무 커지지 않게 함, 파라미터들을 다 더하고 제곱해서 작게 만들어줌 → 뉴럴 네트워크가 만들어내는 함수의 공간 속에서 함수를 부드럽게 만들어주자 (일반화가 잘될것)
Data Augmentation
- 딥러닝에서 데이터가 가장 중요함, 데이터가 많으면 학습 잘 됨
- 데이터가 적을 때는 랜덤포레스트 같은 방법들이 딥러닝보다 잘 됐음, 데이터가 많아지면 딥러닝이 더 잘 됨 → 딥러닝은 많은 데이터에 대해 표현할 수 있음
- 한 레이블에 대해 노이즈가 있는 데이터들이 있다면 이 데이터들을 알맞게 조정해주는 작업 (찌그러진 사진을 펴주는 등)
Noise Robustness
- 입력과 웨이트에 노이즈를 중간중간 넣어주면 테스트에서 좋은 결과 얻을 수 있음
- 왜 잘되는지는 잘 모름
Label Smoothing
- Data Augmentation 과 비슷함
- 실제 성능 많이 올라감
- 학습 데이터 두 개를 뽑아서 섞어줌 (mixup), 이미지에서 descision boundary 를 부드럽게 만들어 줌
- cutmix : 자르고 두 이미지 합침
-
cutout : 일부를 잘라버림

Dropout
- forward 과정에서 일부 웨이트를 0 으로 바꿔서 진행
- 성능 많이 올라감
Batch Normalization
- 논란이 많은 논문, internal covariate shift 가 논란
- BN 을 적용하고자 하는 레이어에 Statistics 를 정규화 시키는 방법 → 각각의 레이어가 1000개의 파라미터가 있다면, 이 파라미터들의 값을 줄여버림 (평균빼고 분산으로 나눔) → internal covariate (feature랑 같은말) shift 를 줄임
-
간단한 분류문제에서 성능 좋음
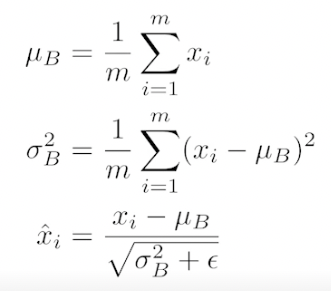
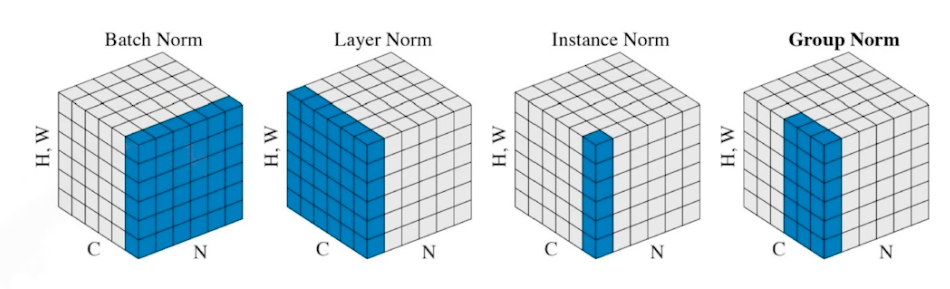
-
여러 종류의 비슷한 방법들이 있음
실습 : 여러 optimizer 사용하여 회귀 문제 해결
- matplotlib 3.2 에서 제공하지 않는 기능을 쓸거라 matplotlib 3.3.0 을 다운받음
- !pip install matplotlib==3.3.0
- 과정
- 필요한 모듈 import and setting
- 데이터셋 만들기
- 모델 정의
- 옵티마이저를 다르게 한 모델 여러개 생성 (SGD, Momentum, Adam)
- 여러 모델 생성
- 여러 옵티마이저 생성 (momentum 은 SGD 에 momentum 파라미터 설정하면 됨)
- 파라미터 체크
- 학습 시작 (Update with optimizers)
- 각 모델에 대해 예측값을 얻음
- 예측값으로 loss 계산
- 옵티마이저 초기화
- loss 미분
- 옵티마이저 스텝 (진행)
- 그림 그려봄
- 결과
- 빨간색 정답
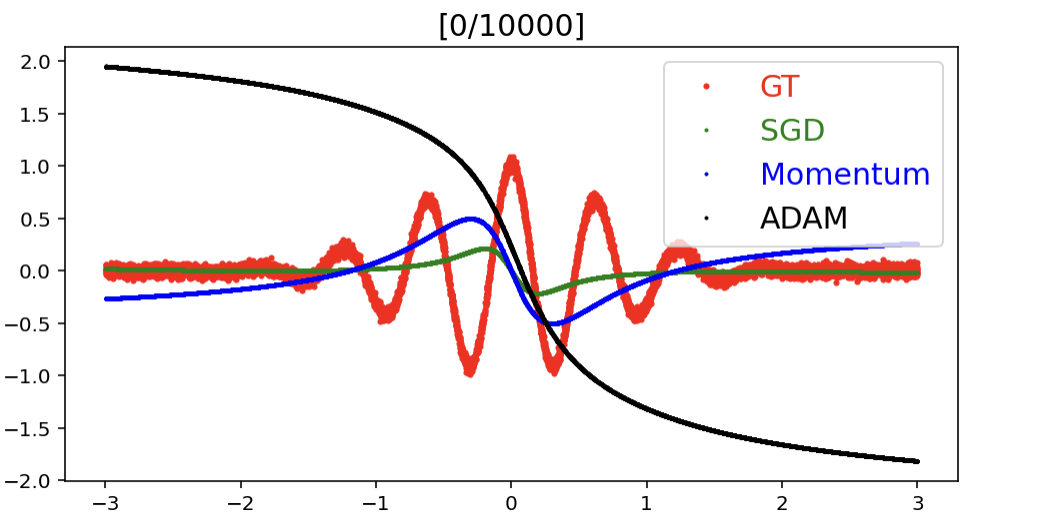
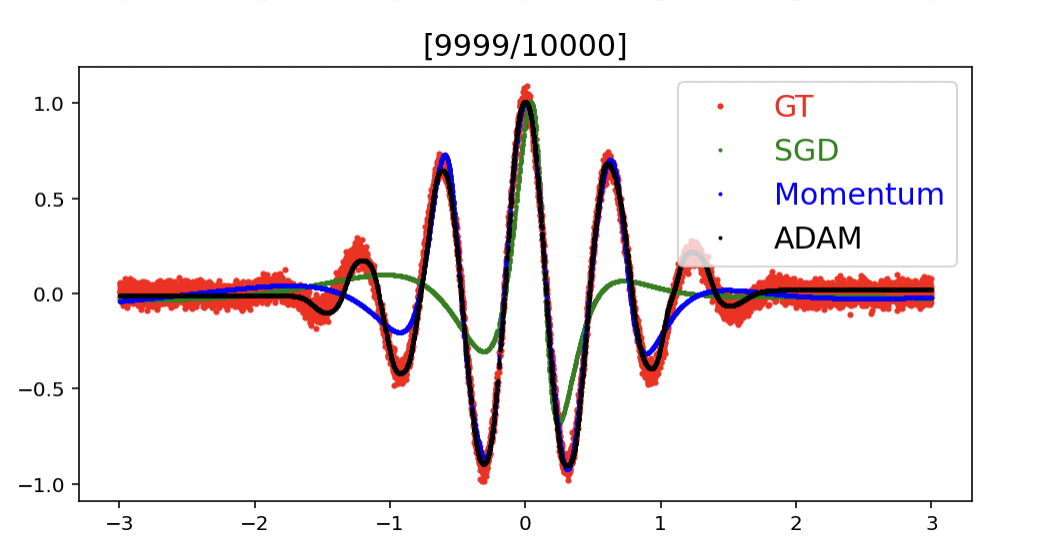
- 모멘텀은 SGD + 이전의 grad 활용 : SGD 보다 모멘텀이 좋음 → SGD 는 iteration 엄청 돌려야 전체 데이터가 수렴가능, 모멘텀은 이전 정보를 활용하므로 데이터를 한번에 더 많이 보는 효과
- ADAM 은 모멘텀 + Adaptive LR 을 합치므로 어느 파라미터는 lr 을 올리고 어느 파라미터는 lr 을 내리므로 훨씬 빠르게 학습
⇒ 많은 이터레이션 + 괜찮은 데이터 (노이즈 적음) 인데도 옵티마이저에 따라 속도와 성능 차이가 남
- 시작은 (R)Adam 쓰자. 그러나 엄청 오랜 시간 지났을 때는 SGD 가 더 좋을 수도 있음.
Further Questions
- 올바르게(?) cross-validation을 하기 위해서는 어떻 방법들이 존재할까요?
- k folds
- 애초에 valid 데이터 빼놓기 6:2:2
- Time series의 경우 일반적인 k-fold cv를 사용해도 될까요?
Further reading
CNN 첫걸음
Convolution 연산 이해하기
- 지금까지 배운 MLP 는 각 뉴런들이 선형모델과 활성함수로 모두 연결된 (fully-connected) 구조였음 → 가중치 행렬 사이즈와 파라미터 수가 큼
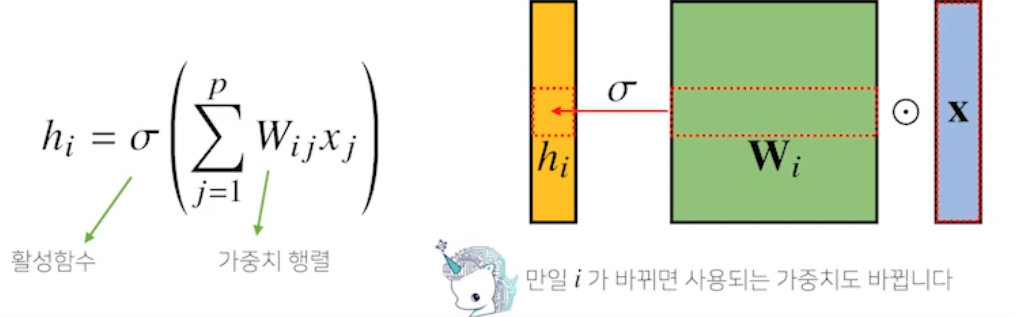
- Convolution 연산은 커널 (kernel) 을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
- V : 커널, k : 커널 사이즈
- 입력벡터 x 를 모두 활용하는게 아니라 k 만큼 추출하여 사용
- 커널은 그대로 두고 커널 사이즈만큼 x 상에서 이동하면서 계산
- i 가 바뀌면 활성화 함수랑 convolution 말고 x 가 움직이며 연산 → 가중치 행렬이 i 에 따라 바뀌는게 아니라 고정된 v 는 움직여가며 연산되는게 차이점
- convolution 연산도 선형변환의 한 종류
- 커널 사이즈는 i 에 관계없고 j 에만 관련 → 파라미터 사이즈 줄어들었음
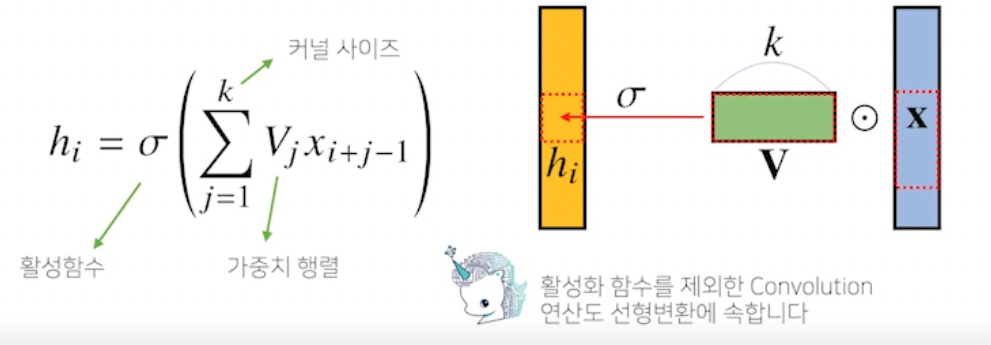
- 수학적 의미
- 신호 (signal) 를 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것

- f 와 g 는 신호 또는 커널임. 파라미터로 x-z 나 i-a 있는게 신호. z 나 a 있는게 커널
- 엄밀한 식은 위의 사진처럼 - 가 아니라 + 를 사용함, 전체적으로는 + 냐 - 냐 (convolution 이냐 cross-correlation 이나 큰 차이없음, 하지만 컴퓨터에서는 중요함) → + 사용 (cross-correlation), 역사적으로 convolution 이라 불러서 그렇게 부름
-
커널은 정의역 내에서 움직여도 변하지 않고 (translation invariant) 주어진 신호에 국소적 (local) 으로 적용됨
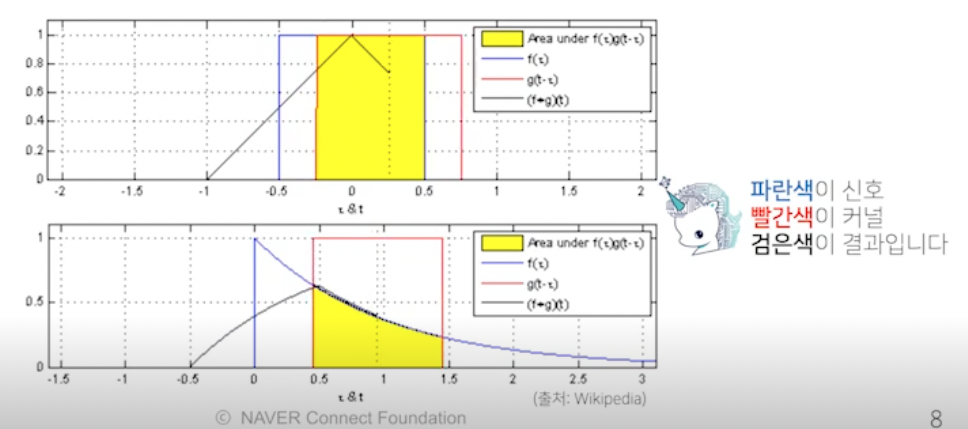
- 빨간색 커널을 움직여서 파란색 신호와 노란색 (국소적) 연산을 통해 검은색 결과가 나옴 → 시그널 (파랑) 을 커널을 통해 바꾸는 작업
영상처리에서 Convolution
- 여러가지 커널 (흐리게, 맑게 등) 을 통해 원하는대로 영상을 추출함
다양한 차원에서의 Convolution
-
Convolution 연산은 1차원뿐만 아니라 다양한 차원에서 계산 가능
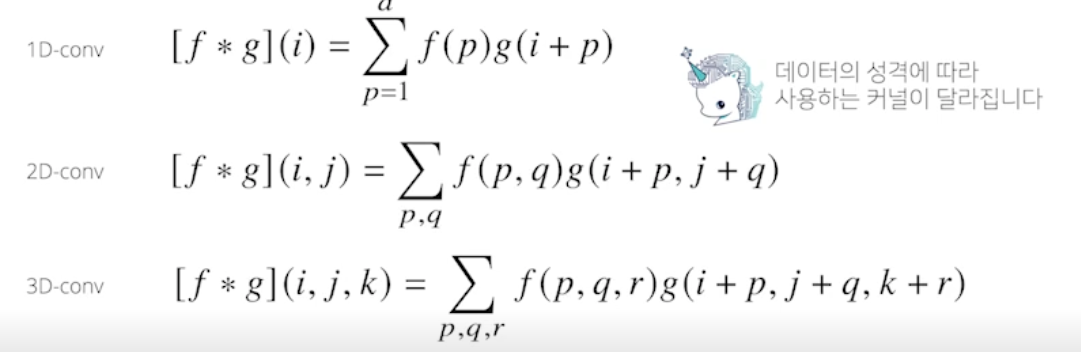
-
차원이 높아져서 i, j, k 가 바껴도 커널 f 의 값은 바뀌지 않음
2 차원 Convolution 연산 이해하기
- 매우 많이 활용되므로 잘 볼 것
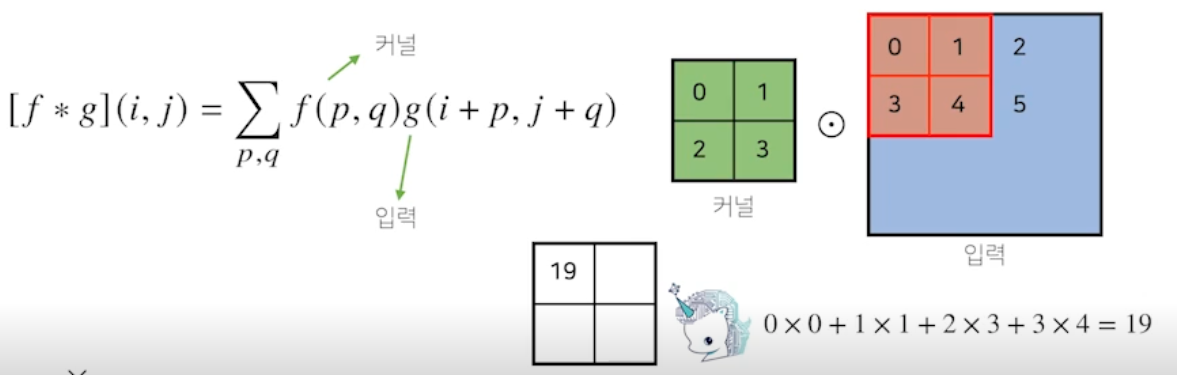
- 2 차원 커널, 행렬 모양의 커널 사용 → 이 커널을 입력벡터 상에서 가로로 세로로 움직이면서 연산
-
마지막에 합성함수 적용
- 입력 크기를 (H, W), 커널 크기를 ($K_H, K_W$), 출력 크기를 ($O_H, O_W$) 라 하면 출력 크기는 다음과 같이 계산

-
채널이 여러개인 2 차원 입력의 경우 2 차원 Convolution 을 채널 개수만큼 적용 (RGB 데이터가 들어오면 2차원 3개 사용, 입력은 3차원 행렬 (텐서), 커널도 3차원 행렬 (텐서)). 텐서를 직육면체 블록으로 이해하면 좀 더 이해하기 쉬움
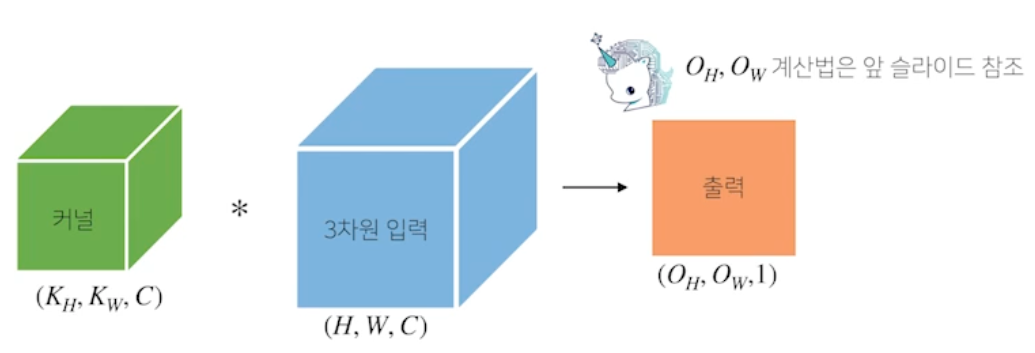
- 커널을 $O_C$ 개 만큼 사용하면 출력도 $O_C$ 텐서로 나옴
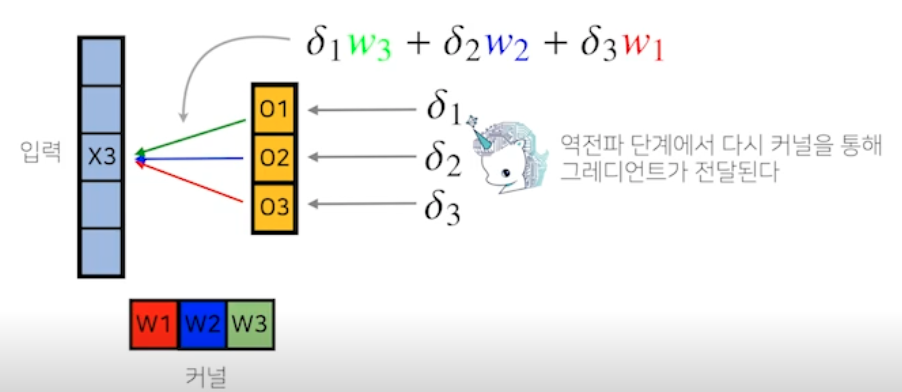
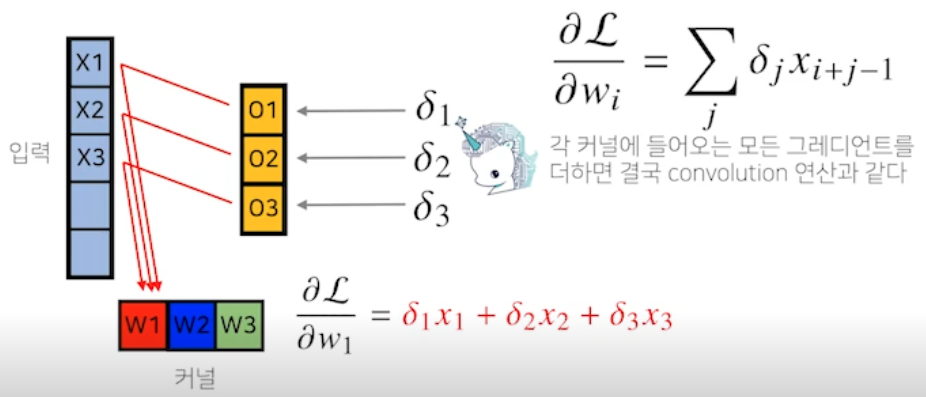
Convolution 연산의 역전파 이해하기
-
Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나옴


-
역전파 그림

피어 세션
수업 질문
TMI 세션
샐리님의 TMI에 대해 알 수 있는 시간이었다 :)
Today I Felt
배우는 즐거움
머신러닝과 딥러닝의 원리나 개념을 잘 모르고 사용했던 지난 날이 부끄러운만큼 딥러닝을 더 자세히 알기 위해 공부하고 있다. 쉽지만은 않지만 즐겁게 공부하고 있다는게 중요한 것 같다. 다른 일을 할 때도 시간나면 머릿속으로 개념정리를 하고 그러다 문득 재밌다는 생각이 들 때면 힘이난다. 정말로 열심히 공부하고 이해해서 이 기술로 사회에 기여할 수 있는 사람이 되고싶다.