목차
베이즈 통계학 맛보기
목표
- 사전확률, 사후확률, evidence 개념을 예제를 통해 정확히 이해할 것
- 인과관계 추론에서 조건부확률을 섣불리 사용하면 안되는 이유 이해할 것
- 중첩효과를 제거함으로써 얻은 인과관계를 어떤 방식으로 활용할 수 있는지 초점을 두고 공부할 것
조건부 확률이란?
- $P(A\ \cap\ B) = P(B)P(A|B)$
- 조건부확률 $P(A|B)$ 는 사건 B 가 일어난 상황에서 사건 A 가 발생할 확률
- 베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려줌
- $P(B|A) = P(A\ \cap\ B)/P(A)\ = P(B)P(A|B)/P(A)$
- A 라는 새로운 정보가 주어졌을 때 $P(B)$ 로부터 $P(B|A)$ 를 계산하는 방법을 제공함
베이즈 정리: 예제
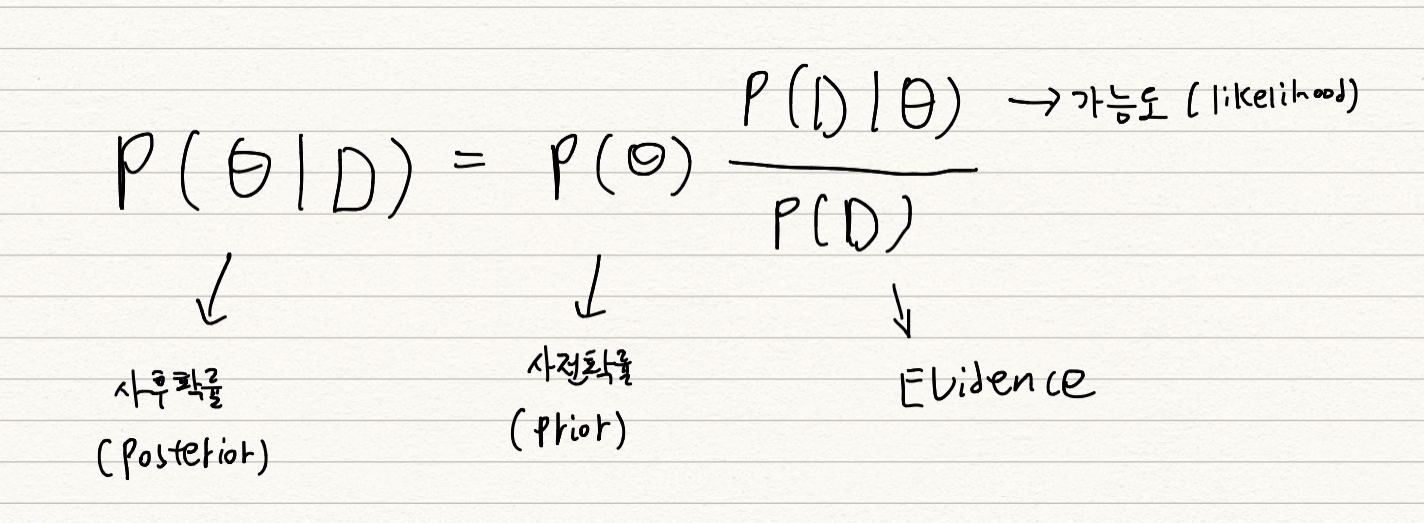
- D : 새로 관찰되는 데이터, $\theta$ : 모델에서 계산하고 싶어하는 모수 (가설)
- 사후확률 : 데이터를 관찰했을 때, 이 가설이 성립할 확률 (데이터 관찰 이후 측정하기 때문에 사후확률)
- 사전확률 : 데이터 없을 때, 가설에 대해 사전에 세운 확률
- 가능도 : 현재 주어진 모수 (가정) 에서 이 데이터가 관찰될 가능성
-
Evidence : 데이터 전체의 분포
→ 가능도와 Evidence 를 통해 사전확률을 사후확률로 업데이트 하는 것!
- COVID-99 의 발병률이 10% 로 알려져있다. COVID-99 에 실제로 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진될 확률이 1% 라고 할 때, 어떤 사람이 질병에 걸렸다고 검진결과가 나왔을 때 정말로 COVID-99 에 감염되었을 확률은?
- 사전확률, 민감도 (Recall), 오탐율 (False alarm) 을 가지고 정밀도 (Precision) 를 계산하는 문제
- $\theta$ 를 COVID-99 발병 사건으로 정의 (관찰 불가) 하고, $D$ 를 테스트 결과라고 정의 (관찰 가능) 함.
- $P(D)$, evidence 를 구해서 풀면됨, $P(D\ |\ \urcorner\theta)$ 를 모르면 풀기 어려움
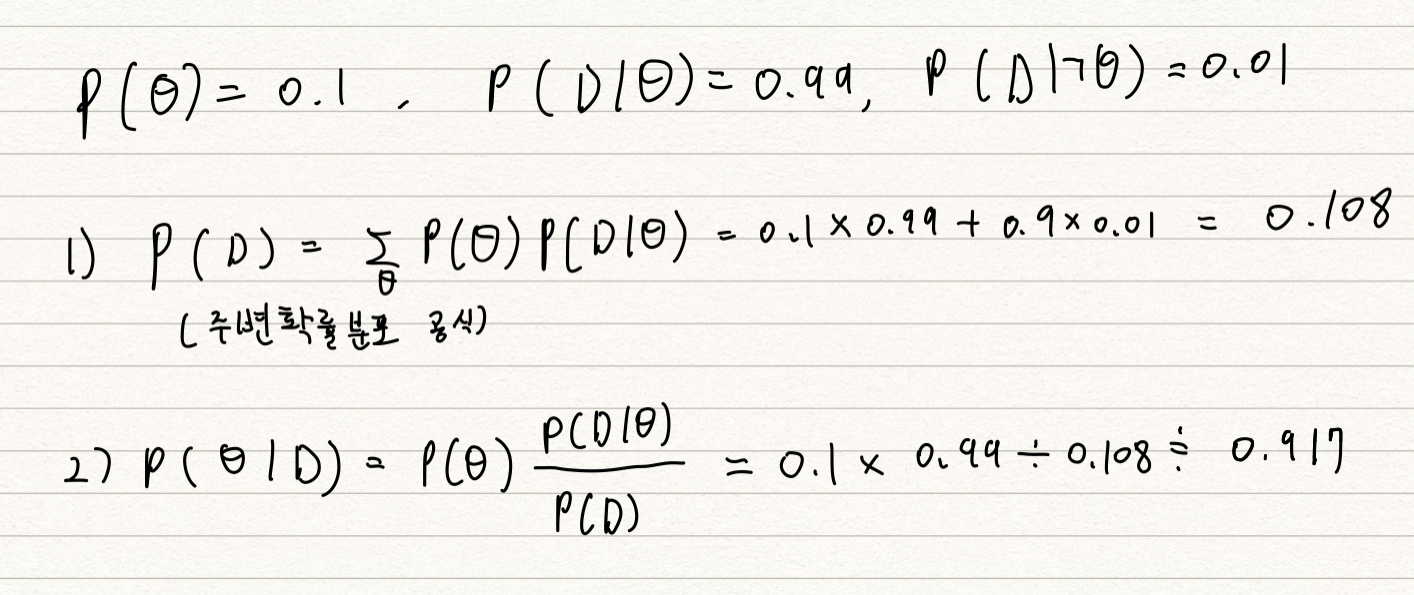
-
만약 오검진될 확률 (1종 오류) 이 1% 가 아닌 10% 가 된다면?
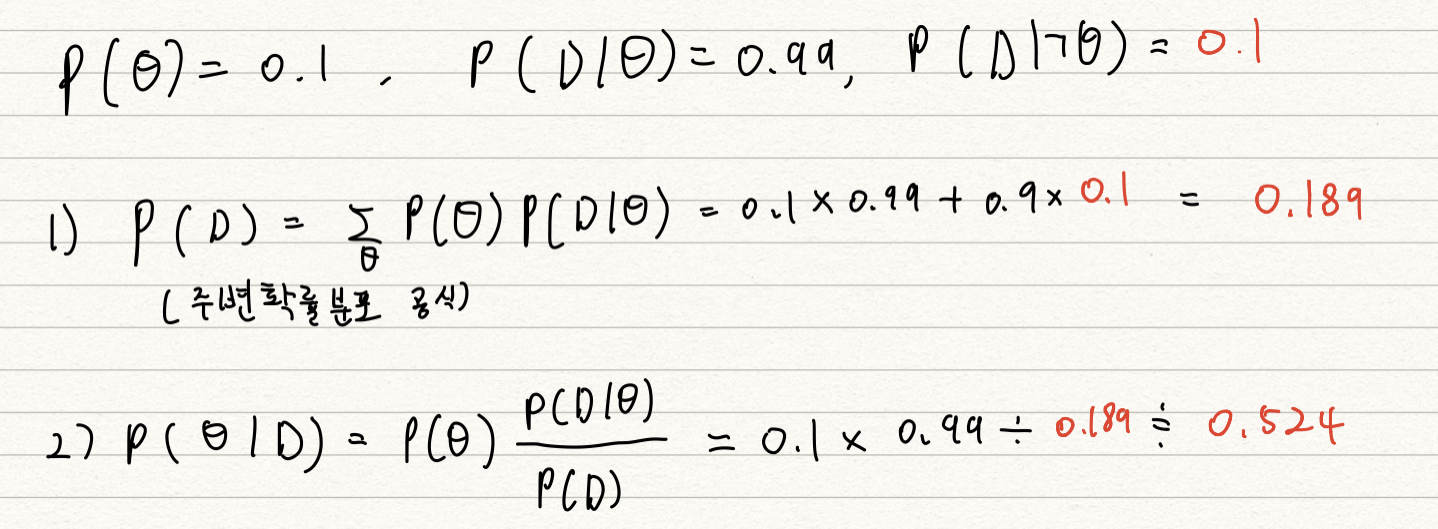
- 오탐율 (False alarm) 이 오르면 테스트의 정밀도 (Precision) 가 떨어짐
조건부 확률의 시각화

- confusion matrix 라고도 함
- True Positive : 양성이 나왔을 때 실제 발병한 경우
- True Negative : 음성이 나왔을 때 발병하지 않은 경우
- False Positive (1종 오류) : 양성이 나왔을 때 발병하지 않은 경우 (False alarm, 오탐과 관련 있음)
- False Negative (2종 오류) : 음성이 나왔을 때 발병한 경우
- 데이터 분석 성격에 따라 1종 오류나 2종 오류 중 중요한게 달라짐, 보통은 1종 오류보다 2종 오류를 더 심각하게 받아들임
- 사전 확률을 모르는 경우 임의 설정 가능하지만, 신뢰도가 떨어짐
- 정밀도는 TP 와 FP 를 분모로 둠, 오탐지율과 민감도가 반영됨
베이즈 정리를 통한 정보의 갱신
- 베이즈 정리를 통해 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산할 수 있음

- 앞서 판정 받은 사람이 두 번째 검진에서도 양성 판정을 받았을 때 진짜 발병했을 확률은?

조건부 확률 → 인과관계?
- 조건부 확률은 유용한 통계적 해석을 제공하지만 인과관계 (causality) 를 추론할 때 함부로 사용해서는 안 됨 (A 가 B 의 원인인가? 같은 문제)
- 데이터가 많아져도 조건부 확률만 가지고 인과관계를 추론하는 것은 불가능
-
인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요, 단, 인과관계 만으로는 높은 예측 정확도를 담보하기는 어려움 (데이터 분포 변화 강건하지만 예측 정확도는 조건부 확률보다 낮다)

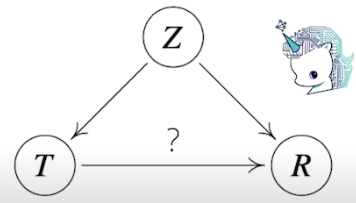
- 인과관계를 알아내기 위해서는 중첩요인 Z (confounding factor) 의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야 함, 만일 Z 의 효과를 제거하지 않으면 가짜 연관성 (spurious correlation) 이 나옴
- 키가 클수록 지능이 좋다 → 어린 아이 (키가 작은) 같이 연령에 따른 지능 지수는 고려하지 않았기 때문에 이런 결과가 나옴
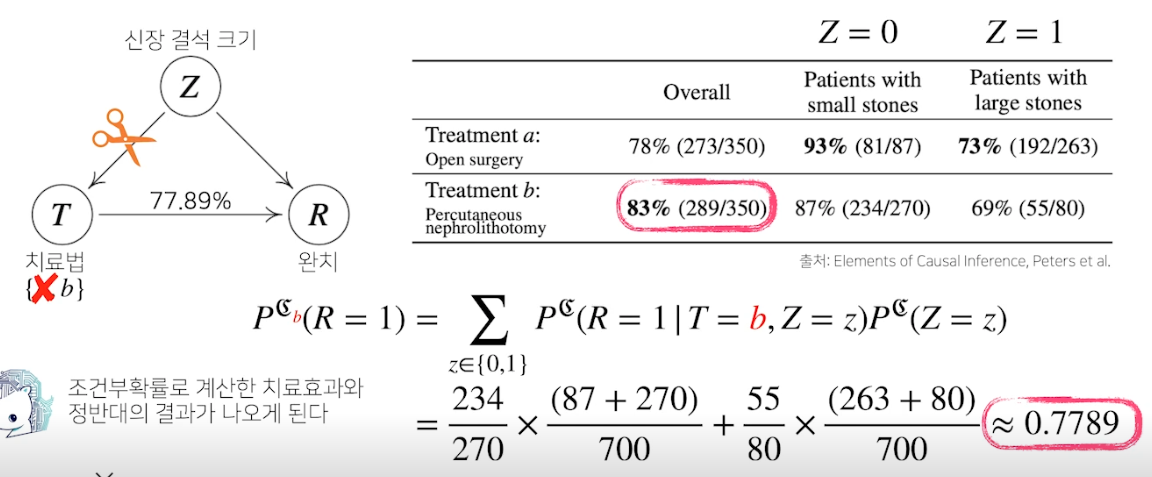
인과관계 추론 : 예제
- 신장 결석 크기에 따라 치료법 a, b 중 선택하는 문제
- 전체적으로 봤을 때는 치료법 b 의 완치율이 높지만 각각의 환자에 대한 완치율을 보면 a 의 완치율이 더 높음 → 전체 평균으로 계산하면 오류를 범함 (심슨 패러독스)
-
조정 효과를 통해 Z 의 개입을 제거함

-
인과 관계 고려한 분석이 조건부보다 더 좋은 결과 나옴, 변수들끼리 관계 파악해야함
딥러닝 기본 용어 설명 - Historical Review
Introduction
- 딥러닝의 분야는 광범위해서 한 사람이 모든 것을 다룰 수 없음, 많은 사람이 다루는 중
- 좋은 딥러너의 조건?
- 구현 스킬 (텐서플로우나 파이토치), 머릿속의 아이디어를 실제로 돌려보는 것
- 수학 스킬 (선형대수학, 확률론 등)
- 많은 최신 논문에 대해 아는 것
- 인간의 지능을 모방하는 인공지능 (AI) ← 머신 러닝 (데이터로 학습) ← 딥러닝 (뉴럴 네트워크를 사용하는 세부적인 분야)
- 뉴럴 네트워크 구조를 사용하면서 데이터로 학습하는 분야!
- 딥러닝의 네가지 주요 요소 (논문을 볼 때도 이 4가지에 집중해서 볼 것)
- 모델이 학습할 데이터
- 데이터 (입력) 를 아웃풋으로 변형시키는 모델
- 모델의 성능을 개선시키는 loss 함수
- loss 를 최소화시키는 변수를 조정하는 알고리즘
Data
- 데이터는 해결하고자 하는 문제의 유형에 의존적임
- Classification, Semantic Segmentation, Detection, Pose Estimation, Visual QnA 등
Model
- 데이터가 주어졌을 때 원하는 결과로 바꿔주는 것
- 결과로 잘 바꿔주기 위한 테크닉 필요
- AlexNet, GoogLeNet, ResNet, LSTM, GAN 등
Loss
- 우리가 얻고자 하는 기준
- 회귀에서는 MSE, 분류 문제에서는 CE, 확률적 모델에서는 MLE 를 최소화 (100% 일치하지는 않음, 왜 쓰는지 고려하고 써야함)
Optimization Algorithm
- SGD, NAG, Adagrad 등 사용하여 loss 최적화
- Dropout, Early stopping 등 사용하여 실제 환경에서 한 번도 보지 못한 데이터에도 잘 동작하도록 하는게 목적
Historical Review
- Denny Britz 페이퍼 기반 설명
- 2012 - AlexNet
- 224 x 224 이미지를 분류하는게 목적
- 이미지넷 대회 1등
- 이전까지는 딥러닝 말고 고전적 방법 사용
- 이후 딥러닝 방법들만 1등함
- 딥러닝 : 블랙매직 (왜 잘되는지 모르지만 잘 됨)
- 이후 기계학습의 판도가 바뀜
- 2013 - DQN
- 딥마인드의 강화학습 모델, Q 러닝을 딥러닝에 적용
- 2014 - Encoder / Decoder
- NMT 문제 해결, 단어 문장을 잘 표현해서 다른 언어의 단어 연속으로 바꾸는게 목적
- seq-seq 모델
- 2014 - Adam Optimizer
- 이제 학습시킬 때 Adam optimizer 사용함
- 왜 쓰는지 보통 사람들 잘 모름, 그냥 씀, 결과가 잘나와서
- 논문들 보면 왜 Adam 썼는지, 왜 러닝레이트를 그렇게 했는지 말 안함 (그냥 그렇게 해야 좋은 성과 나옴)
- 2015 - GAN, Generative Adversarial Network
- 이미지를 생성해냄
- 네트워크가 generator 와 descriminator 를 만들어서 생성해냄
- 2015 - Residual Networks
- 이 논문 덕분에 딥러닝이 딥러닝이 됨
- 딥러닝은 네트워크를 깊게 쌓는 방법, 네트워크를 너무 깊게 쌓으면 트레이닝은 잘 되지만 실제 예측 성능은 좋지 않았음 → ResNet 이 해결
- 여전히 1000단 쌓으면 안되지만, 원래 20단 쌓던거 100단 쌓았을 때도 잘되게 만들어줌
- 2017 - Transformer
- Attention Is All You Need
- 지금은 어텐션이 웬만한 분야 모델 다 이김
- Multi head attention 이해 하는거 중요
- 기존 구조에 비해 어떤 장점이 있는지 중요
- 2018 - BERT
- Bidirectional Encoder Representations from Transformer
- 날씨 예측이나 뉴스 기사 작성 모델을 만들고 싶은데 뉴스 기사 데이터가 별로 없을 때, pre-training 에서는 굉장히 큰 말 뭉치를 사용 → Fine-Tuning 에서 소수의 뉴스 기사 데이터를 줘서 좋은 성능 냄
- 2019 - Big Language Models
- OpenAI 에서 GPT-3 냈음
- 굉장히 많은 파라미터 (1750억개) 를 사용하여 좋은 성능 냄, BERT 의 끝판왕
- 2020 - Self Supervised Learning
- SimCLR : a simple framework for contrastive learning of visual representations
- 한정된 학습 데이터에서는 모델을 바꿔가며 학습하는게 일반적, 이제는 라벨은 모르지만 이미지임은 아는 데이터를 비지도학습 모델에 활용. 어떻게 이미지를 컴퓨터가 이해하는 벡터로 바꿀지 고민.
- 무작위 이미지에서 좋은 피쳐를 뽑아 학습에 이용하겠다.
- 학습데이터를 스스로 만들어내서 (뻥튀기 시켜서) 좋은 성능 만들어내기도 함
PyTorch 시작하기
딥러닝 코드를 처음부터 다 짠다?
- 죽을 수도 있음;;
- 현재는 이렇게 하는 경우 거의 없음
- 스터디용으로는 가능
- 남이 만든 라이브러리, 프레임워크를 씀
- 현재는 텐서플로우+케라스 (TF2.0, 사실상 하나로 나옴, 구글 진영) or 파이토치 (페이스북 진영) 사용
- 텐서플로우 - 하이레벨 (인간친화적), 세션 (공간) 을 마련해두고 값을 주입하는 형태 (어려움)
- 파이토치 - 초기에는 로우레벨, 토치 기반 언어
- 케라스는 텐서플로우를 쉽게 쓰기 위해 사용
- 논문 같은데는 파이토치, 실제 서비스할 때는 텐서플로우도 많이 씀
Pytorch
- Numpy + AutoGrad + Function
- Numpy 구조를 가진 Tensor 객체로 array 표현
- 자동미분을 지원하여 DL 연산 지원
- 다양한 형태의 DL 지원 함수와 모델 지원 (새 논문 나올 때마다 새로 생김)
PyTorch 로 시작하는 딥러닝 입문 책추천
VSCode ssh 사용
- VSCode ssh 를 사용하여 colab 의 원격컴퓨팅 환경을 내 컴퓨터의 vscode 에서 작업할 수 있다.
- 아래 링크 참고
-
실행과정
1) colab 에서 내 구글드라이브 마운트, 인증까지 완료할 것
from google.colab import drive drive.mount('/content/drive')2) cloudflared 실행
from colab_ssh import launch_ssh_cloudflared, init_git_cloudflared launch_ssh_cloudflared(password="cho7611278")3) vscode 에서 실행
- 커맨트+쉬프트+p → connect to host → rank-outdoor-rt-rise.trycloudflare.com 실행후 비밀번호 입력
Tips
- vscode ssh 로 코랩 접속해서 .py 로 작업하는거 추천
- OOP 개념 활용해서 파일들 구분하는거 추천
Pytorch 코드
- import torch 하여 임포트
- torch.FloatTensor() 에 numpy 의 ndarray 를 넣어 1대1 대응 가능
- numpy 의 dot product → matmul 함수
*연산하면 브로드캐스팅 or elementry-wise 연산 일어남 → mul 함수로도 가능- numpy 의 axis → dim 파라미터
- numpy 의 reshape → view 함수
- squeeze 함수 : rank 를 1개 줄임
- unsqueeze 함수 : rank 를 1개 늘림 (둘 다 dim 파라미터 가능)
Pytorch 의 ML/DL formula
- import torch.nn.functional as F
- F.softmax(tensor, dim=0)
-
argmax
y = torch.randint(5, (10,5)) print(y) ''' tensor([[2, 4, 2, 4, 4], [4, 4, 0, 1, 2], [2, 1, 3, 3, 0], [4, 3, 1, 3, 0], [4, 1, 2, 2, 4], [2, 2, 4, 3, 2], [1, 0, 0, 4, 4], [4, 3, 4, 3, 1], [3, 4, 3, 1, 1], [1, 2, 2, 3, 1]]) ''' y_label = y.argmax(dim=1) y_label ''' tensor([1, 0, 2, 4, 0, 0, 0, 4, 2, 2]) ''' - one_hot 함수 사용 가능
-
autograd 함수 자주 사용
$y = w^2$,
$z\ =\ 2\ *\ y\ +\ 5$,
$z\ =\ 2\ *\ w^2\ +\ 5$ 에서 z 미분 구하기w = torch.tensor(2.0, requires_grad=True) y = w**2 z = 2*y + 5 z.backward() w.grad ''' tensor(8.) # z/dw = 4*w -> w = 2 -> 8 '''- backward 의 파라미터로 gradient 를 설정해줄 수도 있음 → 미분할 때 해당 값만큼 곱함
선형회귀에서 autograd
$y = 2*x+1$
import numpy as np
# create dummy data for training
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
import torch
from torch.autograd import Variable
class LinearRegression(torch.nn.Module):
def __init__(self, inputSize, outputSize):
super(LinearRegression, self).__init__()
self.linear = torch.nn.Linear(inputSize, outputSize)
def forward(self, x):
out = self.linear(x)
return out
inputDim = 1 # takes variable 'x'
outputDim = 1 # takes variable 'y'
learningRate = 0.01
epochs = 100
model = LinearRegression(inputDim, outputDim)
##### For GPU #######
if torch.cuda.is_available():
model.cuda()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learningRate)
for epoch in range(epochs):
# Converting inputs and labels to Variable
if torch.cuda.is_available():
inputs = Variable(torch.from_numpy(x_train).cuda())
labels = Variable(torch.from_numpy(y_train).cuda())
else:
inputs = Variable(torch.from_numpy(x_train))
labels = Variable(torch.from_numpy(y_train))
# Clear gradient buffers because we don't want any gradient from previous epoch to carry forward, dont want to cummulate gradients
optimizer.zero_grad()
# get output from the model, given the inputs
outputs = model(inputs)
# get loss for the predicted output
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward()
# update parameters
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
'''
...
epoch 98, loss 0.19512228667736053
tensor(0.1929, device='cuda:0', grad_fn=<MseLossBackward>)
epoch 99, loss 0.1929432600736618
'''
with torch.no_grad(): # we don't need gradients in the testing phase
if torch.cuda.is_available():
predicted = model(Variable(torch.from_numpy(x_train).cuda())).cpu().data.numpy()
else:
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
print(predicted)
'''
[[ 0.1829003]
[ 2.3005698]
[ 4.4182396]
[ 6.535909 ]
[ 8.653579 ]
[10.771248 ]
[12.888918 ]
[15.006587 ]
[17.124256 ]
[19.241926 ]
[21.359596 ]]
'''
- 항상 모듈의 코드가 어떻게 돼있는지 아래 같이 들어가서 확인해보자
교수님 말씀
- pytorch 는 np.ndarray 와 대응된다.
- torch 의 함수들 직접 코드로 들어가서 어떻게 구동되는지 확인하자.
뉴럴 네트워크 - MLP
Neural Networks
- 동물의 뇌를 구성하는 생물학적 뉴런 네트워크에서 애매하게 영향받은 컴퓨터 시스템 (실제 인간의 뇌가 역전파가 일어나느냐? 아니라고 봄, 교수님은 실제 뇌와 비슷한 구조가 아니라고 봄)
- 하늘을 날고 싶다고 해서 비행기가 새처럼 생길 필요는 없음 → 지능을 만들고 싶다해서 인간 뇌구조를 만들 필요는 없음
- 뉴럴 네트워크는 행렬의 연산을 하고 이것을 비선형으로 바꾸는 연산을 반복하는 함수 근사자
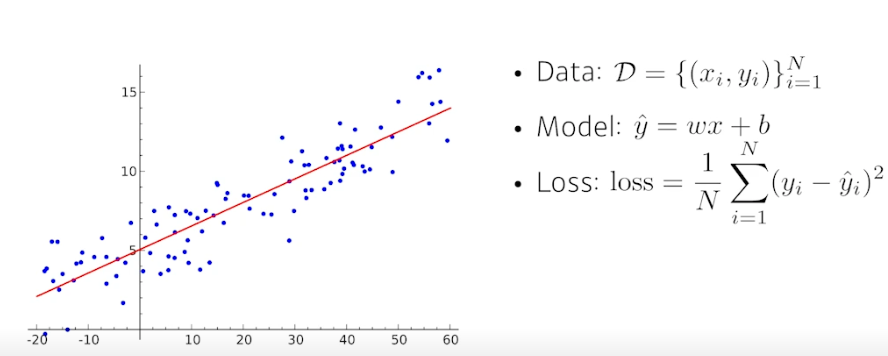
Linear Neural Networks
- Data : 1 차원의 x, y 데이터 1~N 개
- Model : y_hat = wx + b
- Loss : 정답과 예측값 차이의 제곱 평균
- 경사하강법, optimization variables 업데이트하는 방법
- loss 를 w 에 대해 편미분하고 이를 lr 과 곱하여 현재 w 에서 뺌.
- 마찬가지로 b 에 대해서도, loss 를 b 에 대해 편미분하고 이를 lr 과 곱하여 현재 b 에서 뺌.
- 딥러닝에서는 마지막 층의 w 와 시작점에 대한 영향력을 알기 위해 바로 옆 레이어끼리 편미분하여 각각의 값에 경사하강법 수행
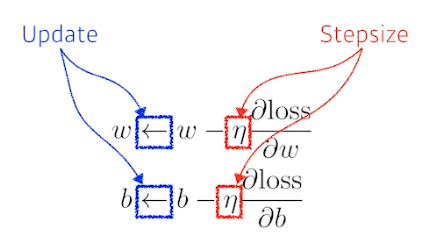
- 적절한 스텝사이즈를 잡아야 함
-
다차원의 input 과 output 이라면 행렬 연산 수행
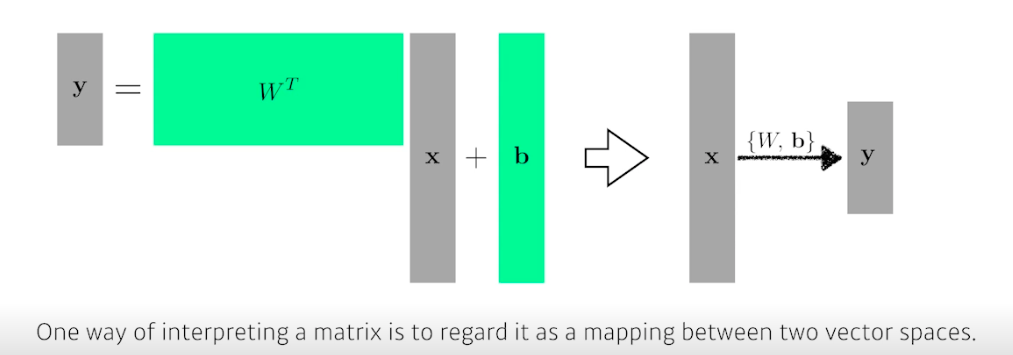
- 행렬은 두 개의 벡터 공간을 선형 변환 (연결) 해주는 것으로 이해 가능
- 딥러닝은 여기서 히든 레이어와 W 를 더 늘려 나감
- 근데 여기서 선형 결합만 계속 반복하는건 1번의 선형결합과 다를게 없음 → 비선형함수와 결합해서 표현을 극대화한 벡터를 얻어서 다음 스텝 수행
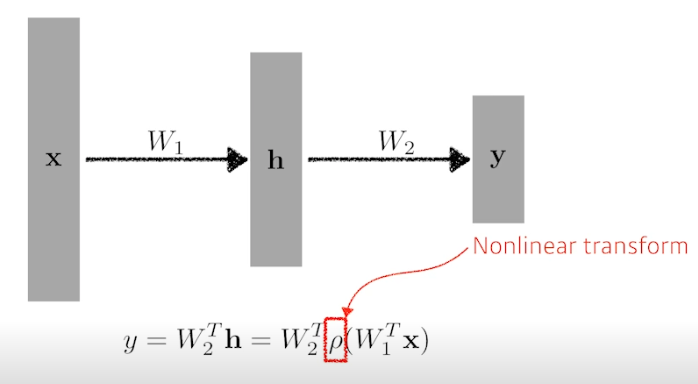
- Activation functions (비선형 함수)
- ReLU
- Sigmoid
- Hyperbolic Tangent (tanh)
- 어떤게 제일 좋을지는 문제마다, 상황마다 다름 → 하지만 딥러닝에서는 꼭 써야함
Multi-Layer Perceptron, MLP
loss functions
- 손실 함수의 목적은 우리가 예측한 값과 실제 값의 차이를 최소화 하는 것
- 꼭 제곱하는 MSE 를 사용할 필요는 없음, 절댓값을 제곱할 수도 있고, 그냥 절댓값 씌울 수도 있음 → 아웃레이어에 대응하다가 거기에 적합한 모델이 되버릴 수도 있음
- 손실 함수가 어떤 성질을 가지고 있고, 이게 왜 내가 원하는 결과를 얻어낼 수 있는지 알아야 함
1) 회귀 문제에서는 MSE 가 적합
2) 분류 문제를 생각해보면, 아웃풋은 one-hot vector 가 나옴 (하나만 1이고 나머지는 0) → Cross-Entropy 를 사용 → 그 차원에 해당하는 값만 키워줌 다른 말로 예측 결과 벡터가 다른 값들에 비해 그냥 높기만 하면 됨 → 이것을 수학적으로 표현해주는게 CE ⇒ 근데 과연 CE 가 분류 문제 푸는데 최적인가? 고민해보고 판단해봐야 함
3) 확률적 문제 (Probabilistic Task) 에서는 MLE(최대가능도) 함수를 사용하여 적절한 모수를 추정 - 사람 얼굴을 보고 나이를 맞추는 문제에서 단순히 나이만 맞추면 회귀 문제
- 20살일 확률, 30살일 확률 등을 알려준다면 확률적 문제
MLP 실습 (MNIST 데이터로 글자 분석)
과정
- numpy, matplotlib, torch 등 다양한 모듈 import 및 현재 장비 (gpu라면 cuda) 체크
- 데이터셋 불러오기.
- torchvision 의 datasets (내장 데이터 사용 가능), transforms 모듈로 데이터 다운로드 및 로드
- Data Iterator, 데이터를 미니배치로 셔플해서 나눔
- 배치 사이즈 정함
- torch.utils.data.DataLoader 로 데이터 로드 및 나눔
- 모델 정의 및 생성
- 모델은 항상 클래스로 만듦, nn.Module 상속 → 기본적인 init, forward 등 사용 가능
- xdim, hdim, ydim 설정
- 원하는 레이어 개수만큼 리니어 레이어 생성
- init_param 을 통해 정규화나 bias 설정
- forward 함수를 통해 선형→활성함수 이러한 작업 가능
- 모델 생성 (gpu로 to(device) 했음), loss 정의, optimizer 정의
- MLP 모델의 간단한 forward path (간단한 테스트인듯) x_numpy → x_torch → y_torch → y_numpy
- 인풋 데이터 x_numpy 를 만듦
- numpy 를 torch 에 넣음. gpu든 cpu든 사용할 디바이스를 마지막에 넣어줘야함, to(device)
- M (모델) 에 x_torch 를 넣어서 학습시킴, forward 함수 실행 (사실 forward 안해도 돌아감, 알아서 forward, 하지만 명시해주는게 나을듯)
- y_torch 로 부터 결과를 detach 하고 이를 numpy 로 변환시켜 y_numpy 에 넣음
- 파라미터 체크
- M.named_parameters() 를 하면 만들어둔 레이어(lin_1, lin_2) 들의 파라미터 weight, bias 가 나옴
- 이를 이용하여 파라미터의 이름, 크기, 값을 확인하는 작업
- Evaluation Function
- with torch.no_grad() : 평가이기 때문에 grad 계산 안함
- model.eval() : model 의 모드를 evaluation 으로 바꿈 (학습할 때 dropout 이나 batch-normalizer 등을 쓰면 트레이닝과 eval의 phase 가 달라져서 해줌)
- test_data 를 배치만큼 쪼개서 반복수행하는데, 모델에 데이터를 넣어 결과값을 얻어냄
- batch_in : 입력 토치, batch_out : 레이블 토치
- 회귀가 아닌 분류 문제이기 때문에 max 를 하여 가장 큰 값 추출 (벡터 → 하나의 값) → 예측값 벡터
- 정확도 계산 : 정답과 예측이 맞는 경우 / 전체 데이터 = 정확도
- 다했으면 다시 model.train() 모드로 바꿔줌
- Train
- 파라미터 초기화, 모델 트레인 모드 세팅, 에포크 설정
- 에포크만큼, 배치만큼 train 데이터를 돌림. 모델에 batch_in 넣고 forward 해서 y_pred 예측값 얻음
- loss 함수에 y_pred 를 넣어 loss_out 을 구함
- 로스를 이용하여 학습을 시킴
- optm.zero_grad() # 옵티마이저 초기화
- loss_out.backward() # 각각의 웨이트에 대해서 편미분 구하기
- optm.step() # 웨이트가 업데이트 됨
- 에포크당 평균 로스 구하기
- 필요할 때마다 정확도 테스트
- Test
- 테스트 데이터로 모델을 돌리고 y_pred 를 얻음
- 원하는 크기만큼 pred 와 label 을 비교하고 그에 맞는 사진을 보여줌
*eval 이나 train 같은 함수들 만들고 나면 반드시 잘되는지 테스트 해줘야함
Further Questions
- Regression Task, Classification Task, Probabilistic Task의 Loss 함수(or 클래스)는 Pytorch에서 어떻게 구현이 되어있을까요?
데이터셋 다루기
self-study guide
- NotMNIST 데이터을 다루는 Dataset class를 만듭니다.
- 데이터셋 파일이 없을 때는 데이터 셋을 download하는 코드를 개발합니다.
- 데이터를 Train / Test로 분리할 수 있도록 Dataset을 클래스를 작성합니다.
- 데이터에서 array를 읽어올 때는 PIL 등의 모듈을 사용할 수 있습니다.
lecture-note-python-basics-for-ai/pytorch/01_mlp
설명
- config.py, main.py, network.py 로 구분돼있음
- config 는 namedtuple 처럼 epoch 등 미리 선언해놓고 다른 곳에서 불러서 씀
- main 에서 모델은 모듈화되어서 여러 모델 (CNN, RNN, MLP 등) 을 끼워넣으면서 돌릴 수 있음
- python3 main.py –epochs 20 해서 돌림
DataLoader
- 나만의 데이터셋을 만들기 위해 torch.utils.data.Dataset 를 상속하는 MyDataSet 클래스 생성
- 매직메소드 init, len, getitem 존재
- dataset = MyDataSet 객체 생성 data_x, data_y 파라미터 필요
- 데이터 로더로 데이터를 아이터레이터로 만들어줌
- dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
- 이미지 데이터를 어떻게 가져오는가?
- PIL 모듈 사용, 경로 잘 맞춰줘야함
from PIL import Image import numpy as np import os print(os.getcwd()) # 현재 디렉토리 경로 나옴 img = Image.open('flag.png') # PATH = os.path.join("/content", "drive", "MyDrive", "flag.png") # 경로 다를 경우 세팅 가능 # img = Image.open(PATH) img # 사진 나옴- 이미지를 데이터 정보로 가져오기
# 픽셀과 색상 np_img_array = np.array(img.getdata()) np_img_array.shape # (614400, 3) # transform : data -> tensor 로 재구성 from torchvision import transforms as transforms result = transforms.ToTensor()(img) result.shape # torch.Size([3, 640, 960]) # 다시 이미지로 바꾸기 img_array = transforms.ToPILImage()(result).convert("RGB") img_array # 사진 나옴 - MNIST 다운하고 사용하기
- 다운로드 파라미터 사용해서 다운로드 시키고 불러옴
- 파고 들어가보면 import urllib 으로 기본 경로 정해져있음 https://yann….
-
따로 설치하는 법
!wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz !gunzip train-images-idx3-ubyte.gz - 어레이로 부르기
- !pip install –user idx2numpy
import idx2numpy import numpy as np file = 'train-images-idx3-ubyte' arr = idx2numpy.convert_from_file(file) arr.shape # (60000, 28, 28) - transform 을 세팅해서 img → 원하는 타입으로 바꿔줄 수 있음
- 참고 : torch 의 기본 데이터셋인 MNIST 는 vision/torchvision/datasets/mnist.py 로 존재
- VisionDataset 클래스 상속한 MNIST 클래스 있음
피어 세션
TED 세미나
- 학부시절, 휠체어 이용자를 위한 어플리케이션을 구글 플레이 스토어에 배포한 경험을 발표하였다.
수업 질문
각자 가장 열심히 한 경험 (자소서 문항 3번)
히스: 어플리케이션 개발
펭귄: 캐글 스터디에서 힘들었던거
서폿: 좌절 후 알고리즘을 열심히 해서 -> 여러 기업 코테통과
샐리: 플젝 (csrt +ssd) 로 ‘실시간’물체 추적
원딜: 졸업플젝 yolo 가지고 높은 온도 위치 찾기
엠제이: 포스코 플젝-> 포즈 측정 손글씨 폰트 샘플로 같은 폰트 글씨 만들기
후미: ocr 책번역기
TMI 세션
- 펭귄님에 대해 잘 알 수 있는 시간이었다!
Today I Felt
휘몰아치는 수업량
오늘은 평소보다 2배 많은 강의가 있었는데, 거의 자정이 되어서야 강의를 다봤다. 복습도 해야하고 나만의 데이터셋 만들기 실습도 해야하는데 할게 정말 많다. 힘들지만 캠프가 끝났을 때의 나를 상상하며 노력해야지!
교수님 면담
오늘 캡스톤 지도 교수님이셨던 Henry Choi 교수님을 찾아뵀다. 근황도 전하고 AI 진로에 대해 조언도 해주셔서 감사했다. 그치만 애매한 나의 학점 때문에 이를 메우기 위해서는 실력이 필요하다 말씀하셨고, 캠프하면서 남들보다 더 노력하라 말씀하셨다. 정말 감사한 조언이었다. 진로가 취업이 될지 대학원이 될지 아무것도 모르지만 우선은 실력을 갈고 닦아 어디서든 쓰임 받을 수 있는 인재가 되도록 노력해야함을 느꼈다.