목차
그래프의 구조를 어떻게 분석할까?
군집
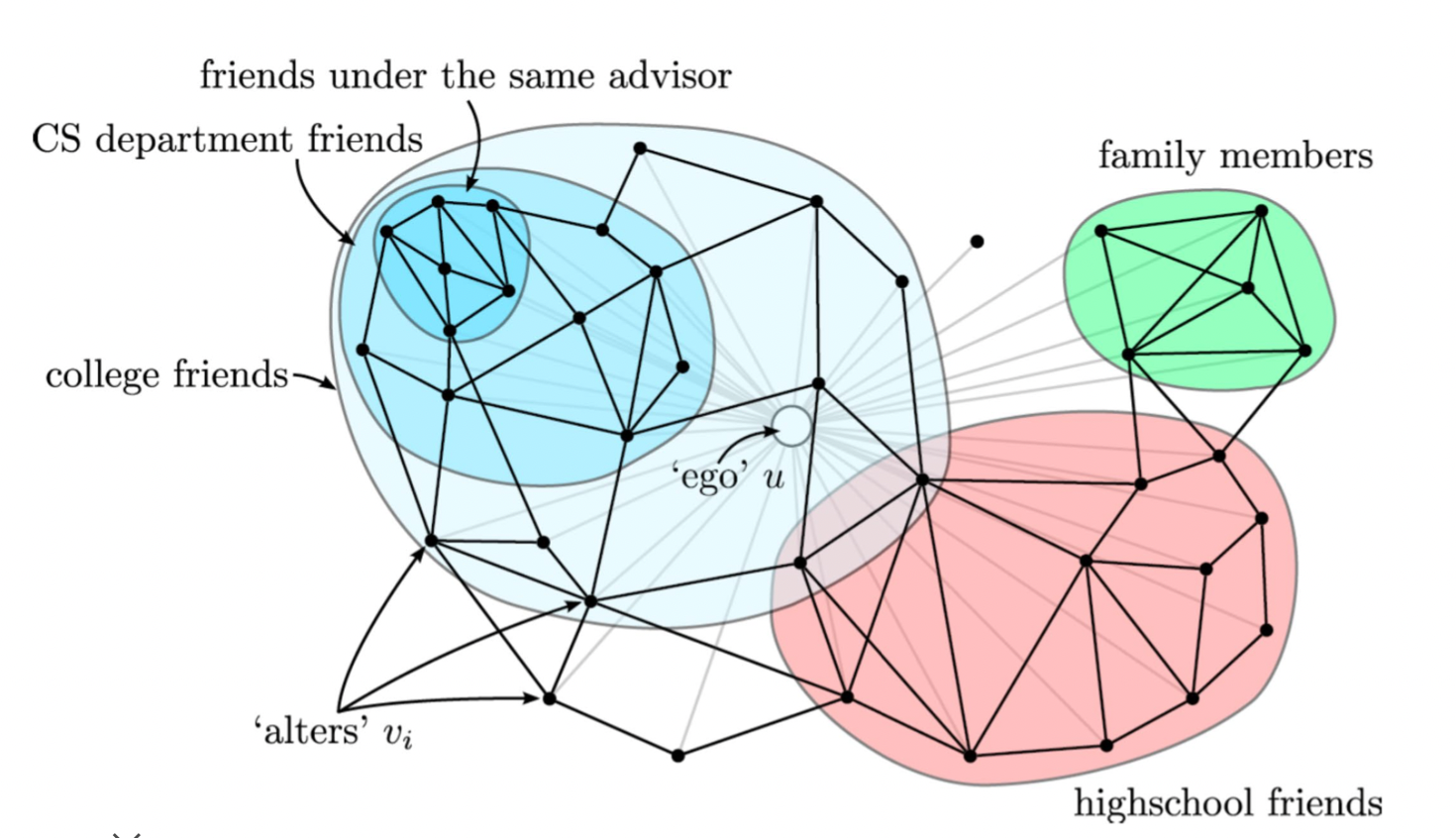
- 온라인 소셜 네트워크의 군집들은 사회적 무리 (Social Circle) 을 의미하는 경우가 많음
- 소셜 네트워크의 군집들이 부정 행위와 관련된 경우도 있음
- 조직 내 분란이 소셜 네트워크 상의 군집으로 표현된 경우도 있음
- 뉴런간 연결 그래프에서는 군집들이 뇌의 특정 기능을 담당
-> 이렇듯 군집은 정점 간의 특별한 관계를 알려주기도 함
군집 탐색 문제
- 그래프를 여러 군집으로 잘 나누는 문제를 군집 탐색 (Community Detection) 문제라 함
- 보통은 각 정점이 한 개의 군집에 속하도록 나눔
- 비지도 기계학습 문제인 클러스터링과 유사
군집 구조의 통계적 유의성과 군집성
비교 대상 : 배치 모형
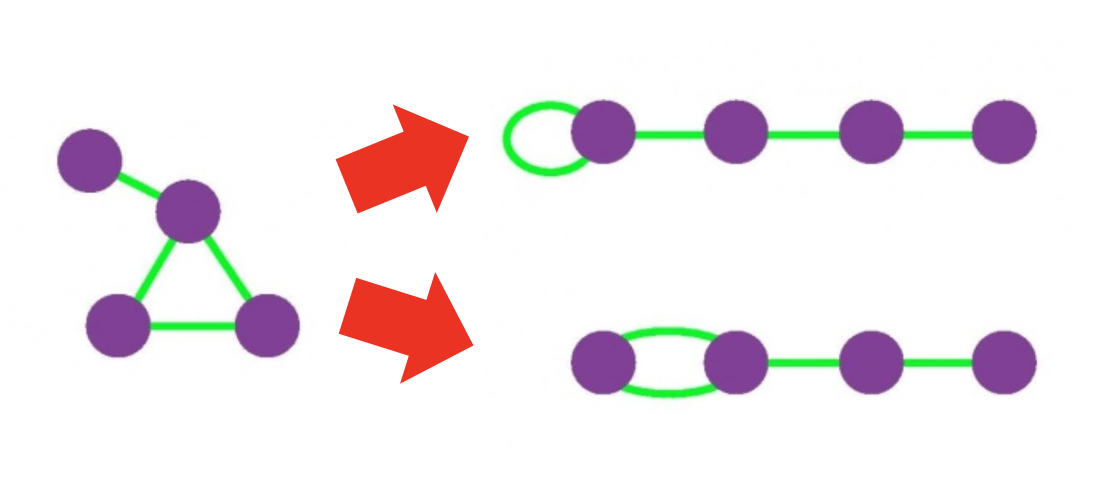
- 성공적인 군집 탐색을 정의하기 위해 배치 모형 사용
- 주어진 그래프에 대한 배치 모형은 각 정점의 연결성을 보존한 상태에서 간선들을 무작위로 재배치하여 얻은 그래프를 의미함
- 배치 모형에서 임의의 두 정점 i 와 j 사이에 간선이 존재할 확률은 두 정점의 연결성에 비례
군집성
- 군집 탐색의 성공 여부를 판단하기 위해 군집성 사용
-
그래프와 군집들의 집합 S 가 주어졌을 때 각 군집 s 가 군집의 성질을 잘 만족하는지 살펴보기 위해, 군집 내부의 간선의 수를 그래프와 배치 모형에서 비교

- 기댓값 사용하는 이유 : 배치 모형이 무작위성을 포함하기 때문
- -1 ≤ 군집성 ≤ 1
- 배치 모형과 비교해서 그래프에서 군집 내부 간선의 수가 많을 수록, 위 식의 값이 커질 수록 성공한 군집 탐색
- 군집성은 무작위로 연결된 배치 모형과의 비교를 통해 통계적 유의성을 판단
- 항상 -1 과 1 사이의 값을 가짐
- 0.3~0.7 정도 값을 가질 때 그래프에 존재하는 통계적으로 유의미한 군집들을 찾아냈다고 볼 수 있음
- 예시
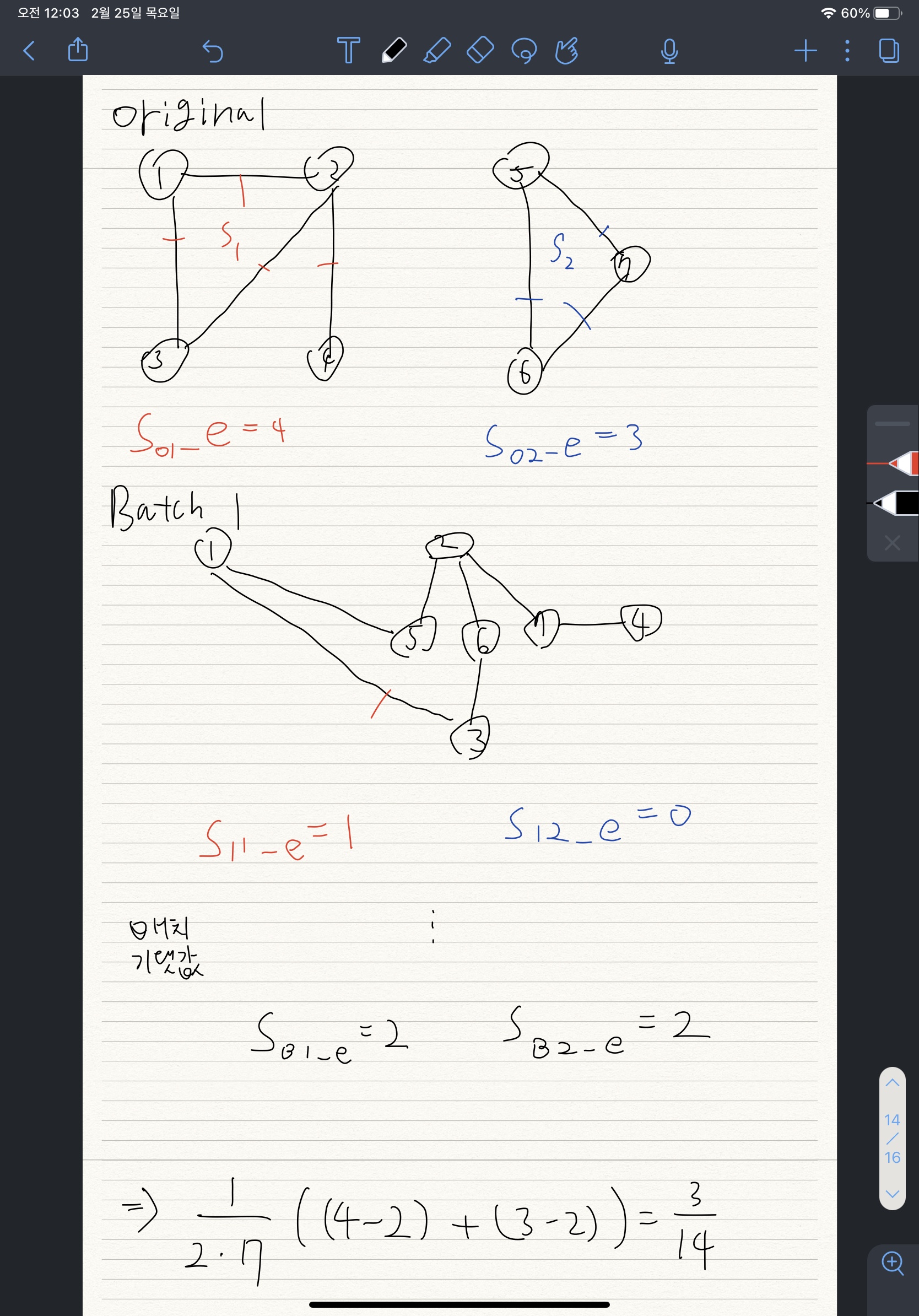
- 배치 모형은 전체 그래프에 대해 만들고 해당 군집 노드끼리 연결되는 엣지만 체크함
군집 탐색 알고리즘
Girvan-Newman 알고리즘
- 하향식, 탑-다운 군집 탐색 알고리즘
- 전체 그래프에서 탐색을 시작해서 군집들이 서로 분리되도록 간선을 순차적으로 제거
- 서로 다른 군집을 연결하는 다리 역할의 간선을 제거
- 다리 역할의 간선을 어떻게 찾을 수 있을까?
- 간선의 매개 중심성 (Betweenness Centrality) 사용
- 해당 간선이 정점 간의 최단 경로에 놓이는 횟수
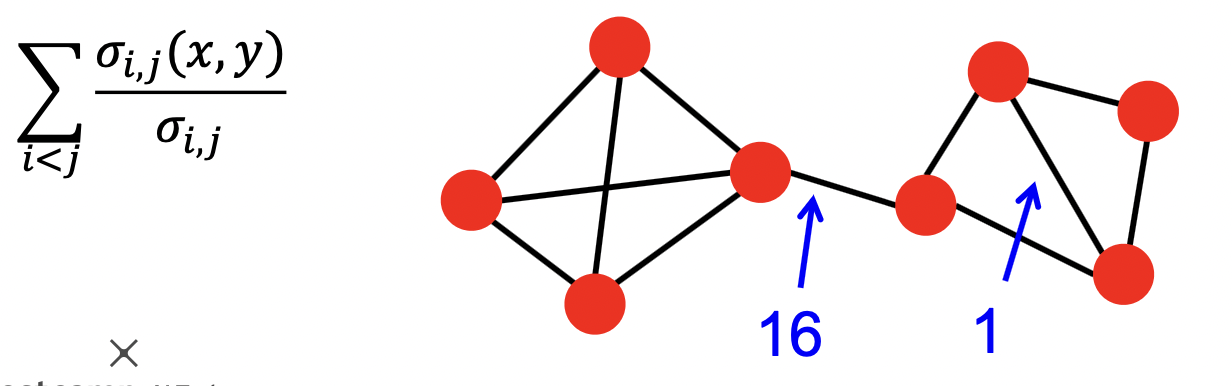
- 매개 중심성이 높은 간선을 순차적으로 제거
- 단계마다 새로 매개 중심성 파악
- 모든 간선이 제거될 때까지 수행
- iteration 에 따라 다른 입도 (Granularity) 의 군집 구조가 나타남
- 간선을 어느 정도 제거하는 것이 가장 적합할까?
- 군집성이 최대가 되는 지점까지 간선 제거
- 단, 현재의 연결 요소들을 군집으로 가정하되, 입력 그래프에서 군집성 계산
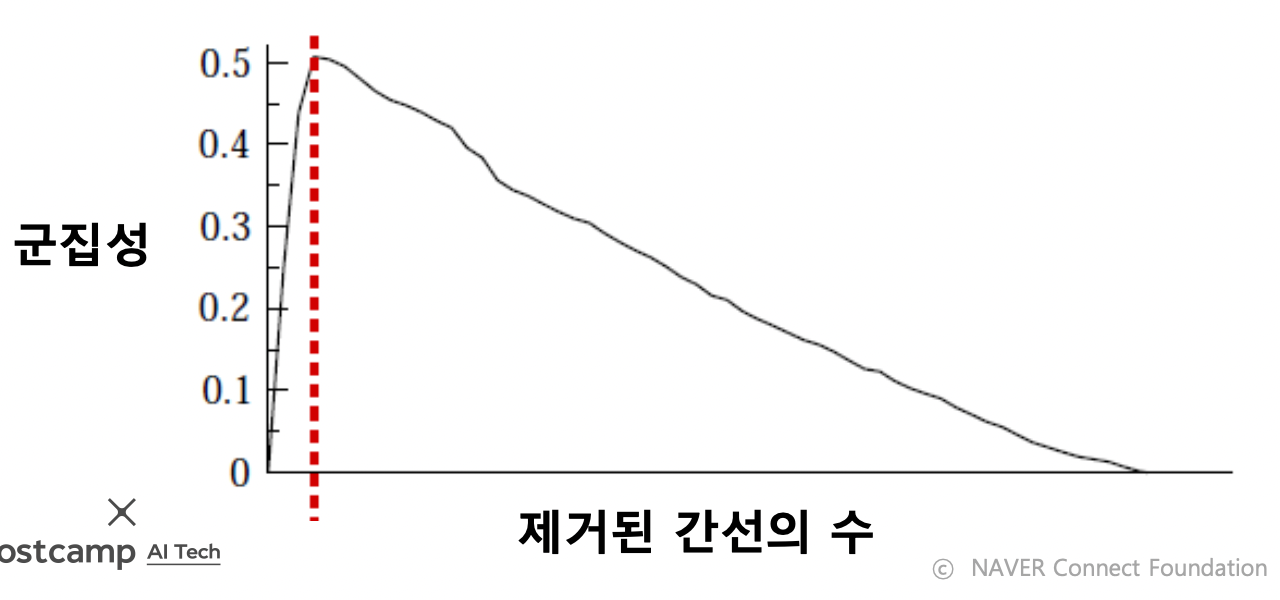
- 과정 정리
- 전체 그래프에서 시작
- 매개 중심성이 높은 순서로 간선 제거하면서 군집성의 변화를 기록
- 군집성이 가장 커지는 상황 복원
- 이 때 서로 연결된 정점들, 연결 요소를 하나의 군집으로 간주
Louvain 알고리즘
- 상향식, 바텀-업 군집 탐색 알고리즘
- 개별 정점에서 시작해서 점점 큰 군집 형성
- 어떤 기준으로 군집을 합칠까?
- 군집성
- 과정 정리
- 1) 개별 정점으로 구성된, 크기 1의 군집들로부터 시작
- 2) 각 정점 u 를 기존 혹은 새로운 군집으로 이동함. 이 때, 군집성이 최대화되도록 군집을 결정
- 3) 더이상 군집성이 증가하지 않을 때까지 2) 반복
- 4) 각 군집을 하나의 정점으로하는 군집 레벨의 그래프를 얻은 뒤 3) 을 수행
- 5) 한 개의 정점이 남을 때까지 4) 반복
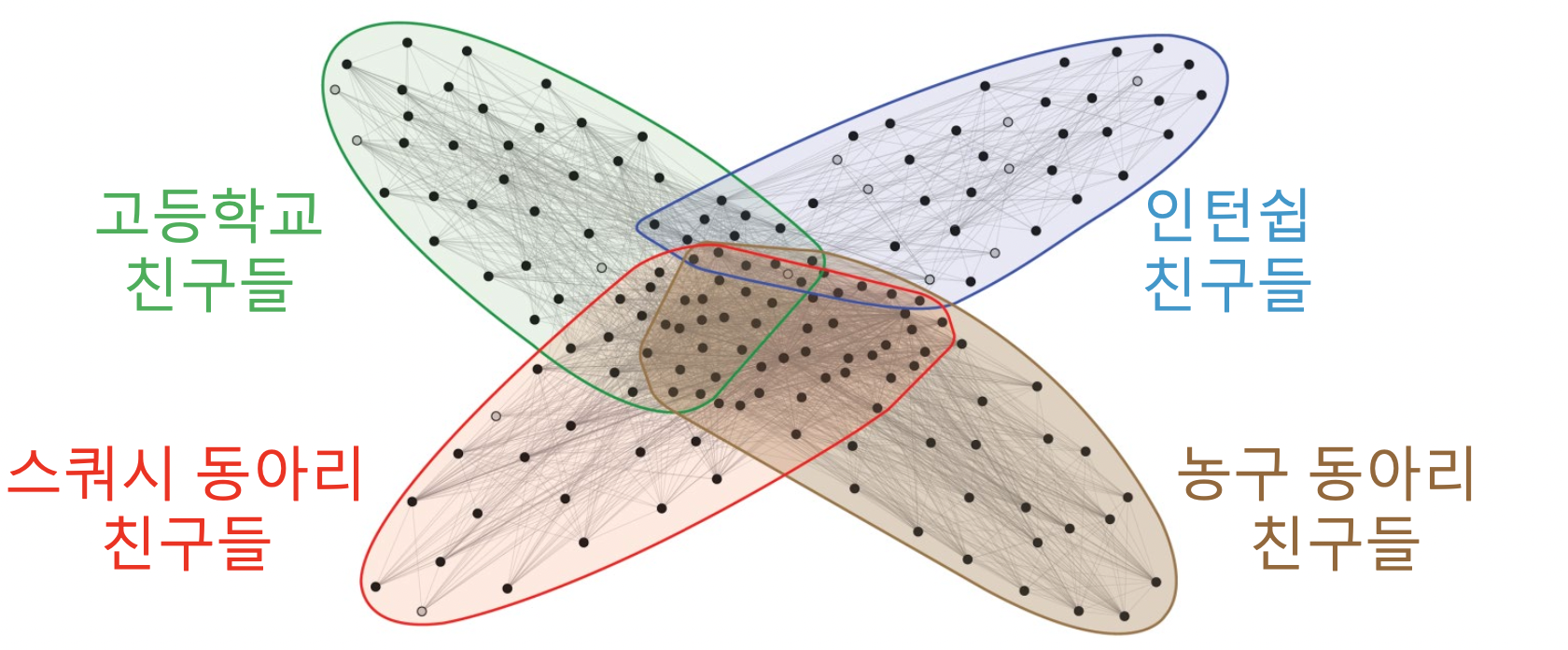
중첩이 있는 군집 탐색
- 실제 그래프의 군집들은 중첩되어 있는 경우가 많음
- 소셜 네트워크에서 개인은 여러 사회적 역할을 수행
- 위의 두 알고리즘은 한 정점은 한 군집이라 가정했음
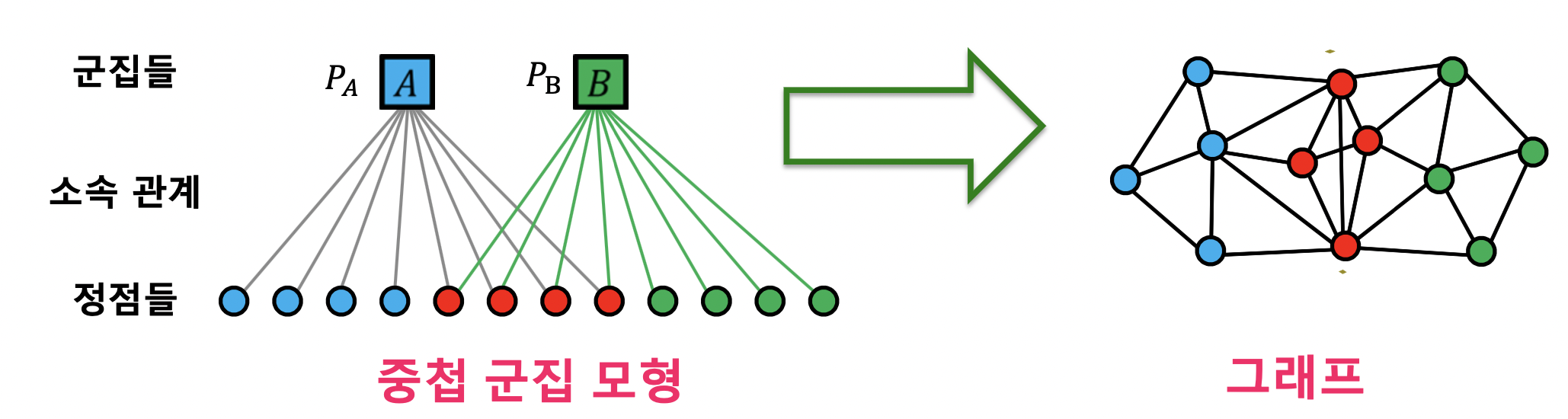
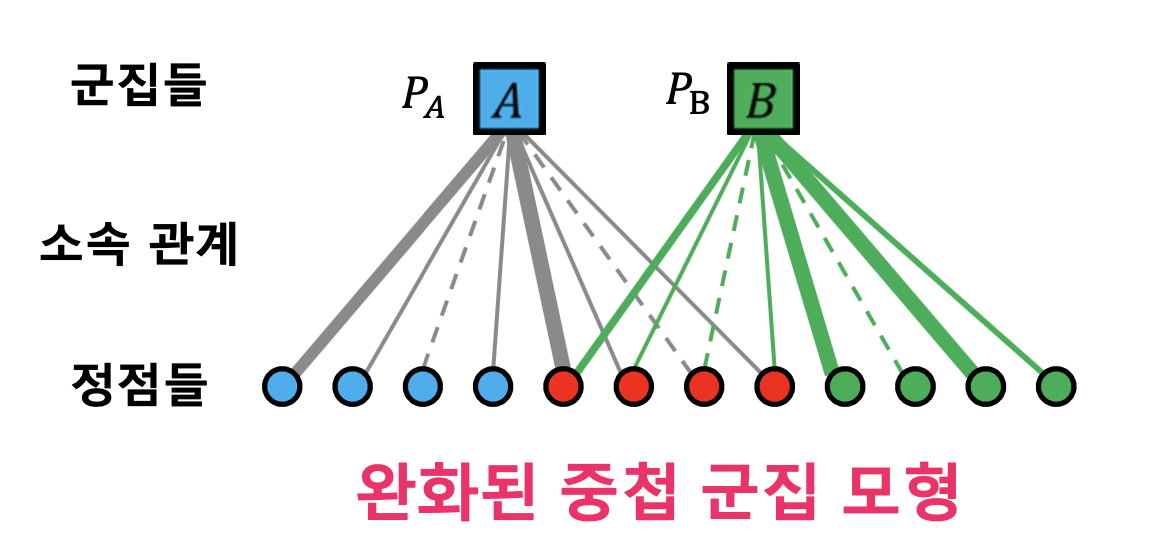
- 중첩 군집 모형
- 각 정점은 여러 개의 군집에 속할 수 있음
- 각 군집 A 에 대하여 같은 군집에 속하는 두 정점은 $P_A$ 확률로 간선 연결
- 두 정점이 여러 군집에 동시에 속할 경우 간선 연결 확률은 독립적
- A 와 B 에 동시에 속할 경우 두 정점이 간선으로 직접 연결될 확률은 1-(1-PA)(1-PB)
- 어느 군집에도 함께 속하지 않는 두 정점은 낮은 확률 e 로 직접 연결됨
- 중첩 군집 모형이 주어지면, 주어진 그래프의 확률을 계산할 수 있음
- 그래프의 확률은 다음 확률들의 곱
- 그래프의 각 간선의 두 정점이 (모형에 의해) 직접 연결될 확률
- 그래프에서 직접 연결되지 않은 각 정점 쌍이 (모형에 의해) 직접 연결되지 않을 확률
- 그래프의 확률은 다음 확률들의 곱
- 중첩 군집 탐색은 주어진 그래프의 확률을 최대화하는 중첩 군집 모형을 찾는 과정
- 최우도 추정치 (MLE) 를 찾는 과정
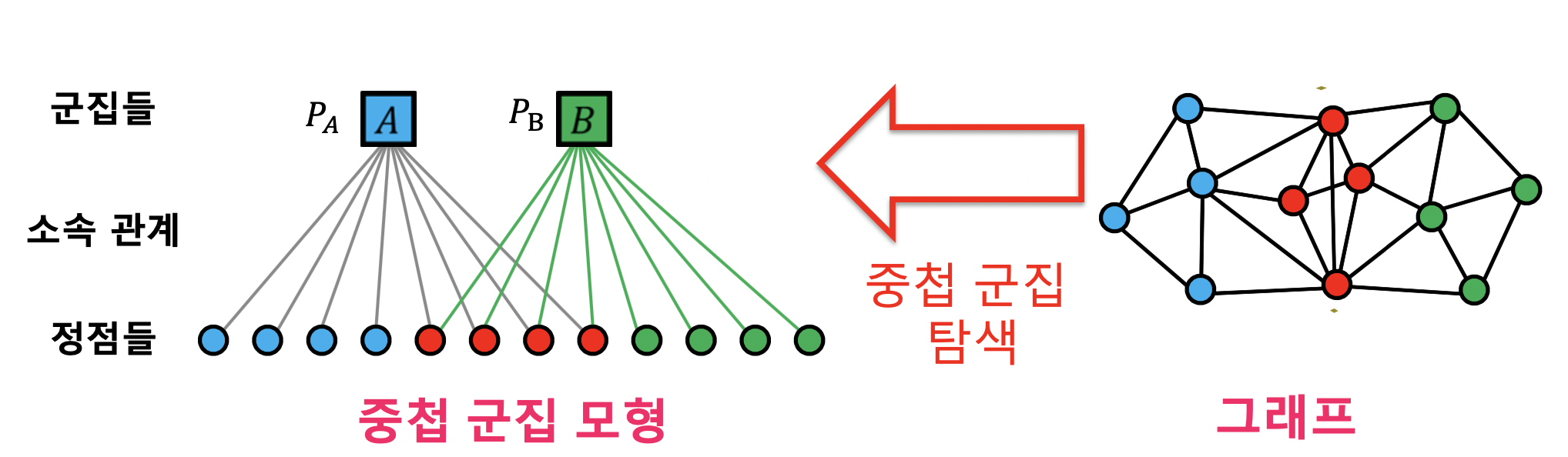
- 각 정점이 각 군집에 속한다, 속하지 않는다 (1, 0) 이산적으로 나오기 때문에 최적화 방법 (경사하강법 등) 을 사용할 수 없어서 중첩 군집 탐색 힘듦
완화된 중첩 군집 모형
- 완화된 중첩 군집 모형을 통해 중첩 군집 탐색 용이해짐
-
각 정점이 각 군집에 속해 있는 정도를 실숫값으로 표현, 중간 상태 표현 가능
- 모형의 매개변수들이 실숫값을 가지므로 최적화 도구 (경사하강법 등) 을 사용하여 모형을 탐색할 수 있음
Further Reading
그래프를 추천 시스템에 어떻게 활용할까? (기본)
우리 주변의 추천 시스템
- 아마존
- 메인 페이지 고객 맞춤형 상품 목록
- 특정 상품을 살펴볼 때 함께 or 대신 구매할 상품 목록
- 넷플릭스
- 메인 페이지 고객 맞춤형 영화 목록
- 유튜브
- 메인 페이지 고객 맞춤형 영상 목록
- 현재 재생 중인 영상과 관련된 영상 목록
- 페이스북
- 추천 친구 목록
- 추천 시스템과 그래프
- 사용자 각각이 구매할 만한 혹은 선호할 만한 상품을 추천함
- 그래프 관점에서 추천 시스템은 ‘미래의 간선을 예측하는 문제’ 혹은 ‘누락된 간선의 가중치를 추정하는 문제’
내용 기반 추천 시스템
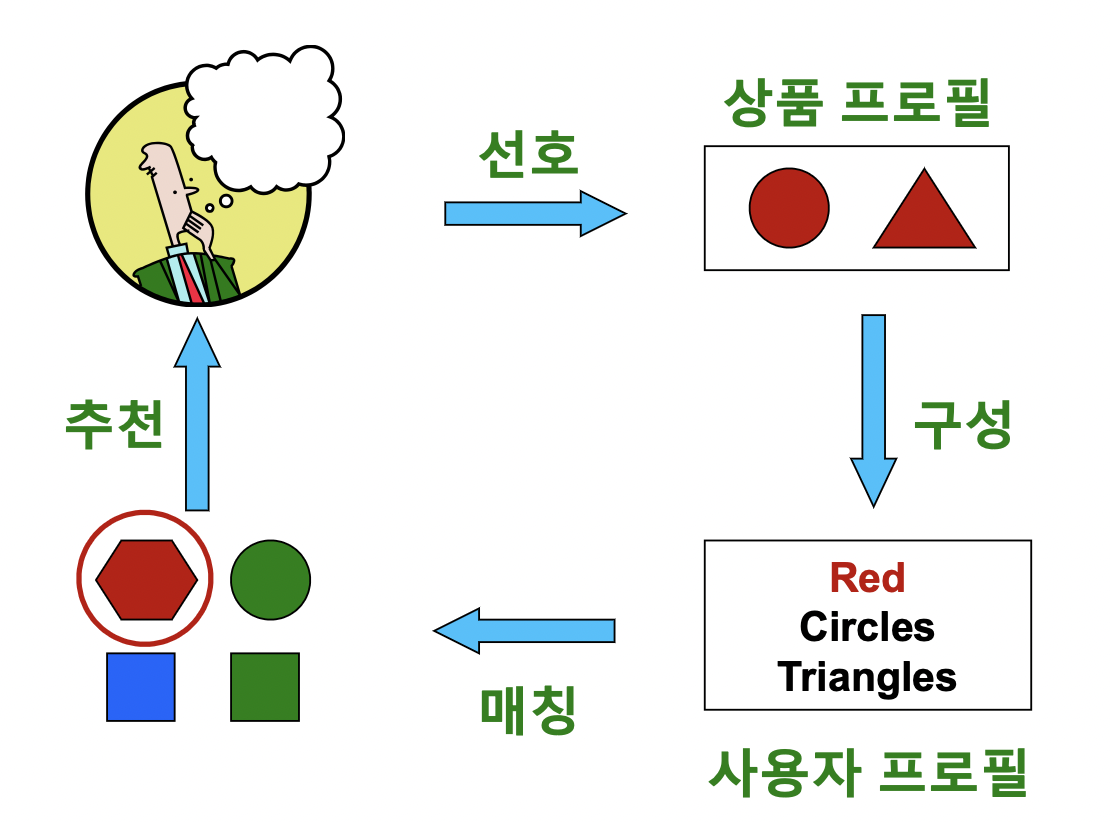
- 각 사용자가 구매 / 만족했던 상품과 유사한 것을 추천
- 동일한 장르의 영화 추천, 동일한 감독 영화, 동일한 배우 출현 영화 추천
- 동일한 카테고리 상품 추천
- 동갑의 같은 학교 졸업한 학생 친구로 추천
- 단계
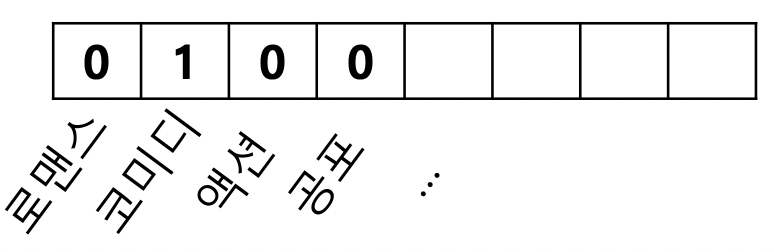
- 1) 사용자가 선호했던 상품들의 상품 프로필 (Item Profile) 수집
- 상품 프로필은 해당 상품의 특성을 나열한 벡터, 영화의 경우 감독, 장르, 배우 등의 원-핫 인코딩이 상품 프로필이 됨
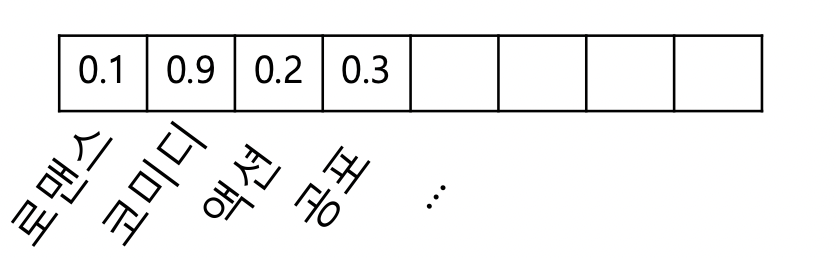
- 2) 사용자 프로필 (User Profile) 구성
- 사용자 프로필은 선호한 상품들의 상품 프로필을 가중 평균하여 계산. 사용자 프로필 역시 벡터.
- 3) 사용자 프로필과 다른 상품들의 상품 프로필을 매칭
- 사용자 프로필 벡터 u 와 상품 프로필 벡터 v 에 대해 코사인 유사도 (내적/두벡터크기곱) 계산
- 사용자가 빨간 원, 빨간 삼각형을 선호했다면, 빨강 1, 원 0.5, 삼각형 0.5 이므로 후보들과 코사인 유사도를 계산하면 빨간 상품이 추천될 확률이 높음
- 4) 사용자에게 상품을 추천. 계산한 코사인 유사도가 높은 상품 추천
- 1) 사용자가 선호했던 상품들의 상품 프로필 (Item Profile) 수집
- 장점
- 다른 사용자의 구매 기록이 필요하지 않음 (자기 기록만 사용)
- 독특한 취향의 사용자에게도 추천 가능
- 새 상품에 대해서도 추천 가능
- 추천의 이유를 제공할 수 있음
- 빨간색 선호하니까 빨간색 추천
- 단점
- 상품에 대한 부가 정보가 없는 경우 사용 불가
- 구매 기록이 없는 사용자에게는 사용할 수 없음
- 과적합(오버피팅) 으로 지나치게 협소한 추천을 할 위험이 있음
- 빨간색만 계속 추천
협업 필터링
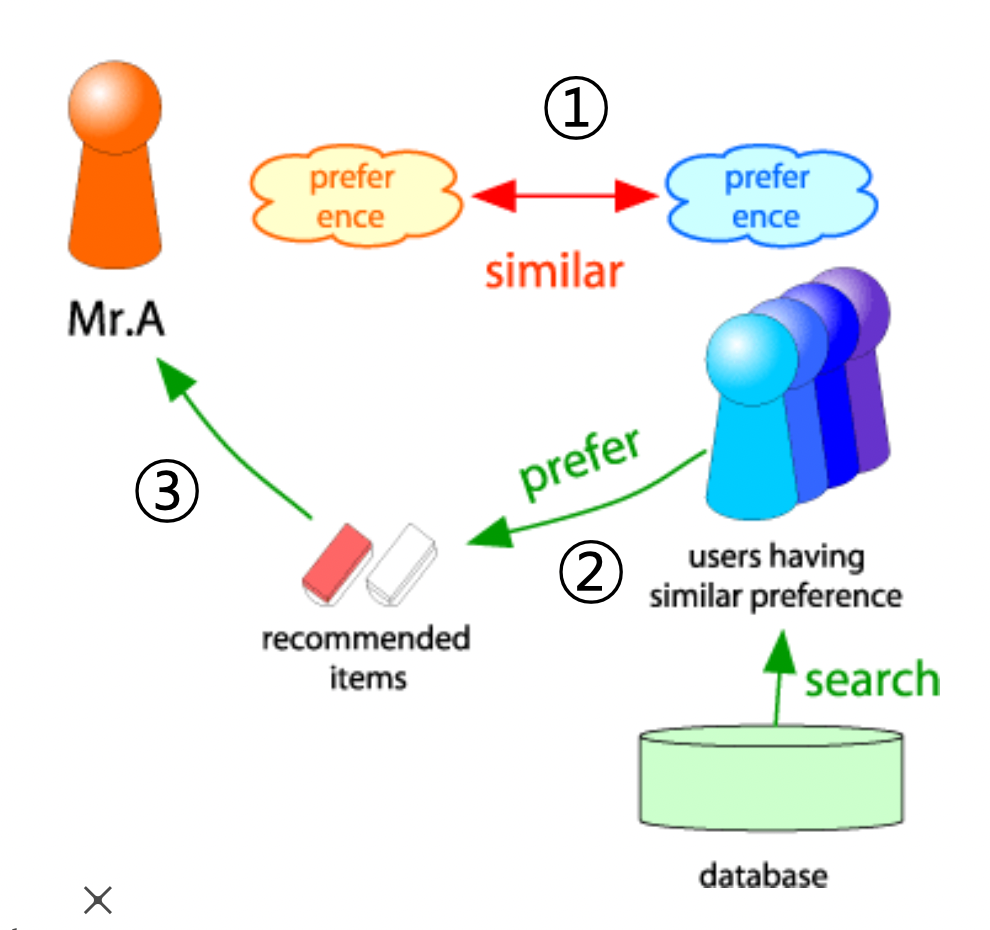
- 사용자-사용자 협업 필터링
- 단계
- 1) 대상 사용자 x 와 유사한 취향의 사용자들을 찾음
- 2) 유사한 취향의 사용자들이 선호한 상품을 찾음
- 3) 이 상품들을 x 에게 추천함
-
취향의 유사도를 어떻게 계산할까?
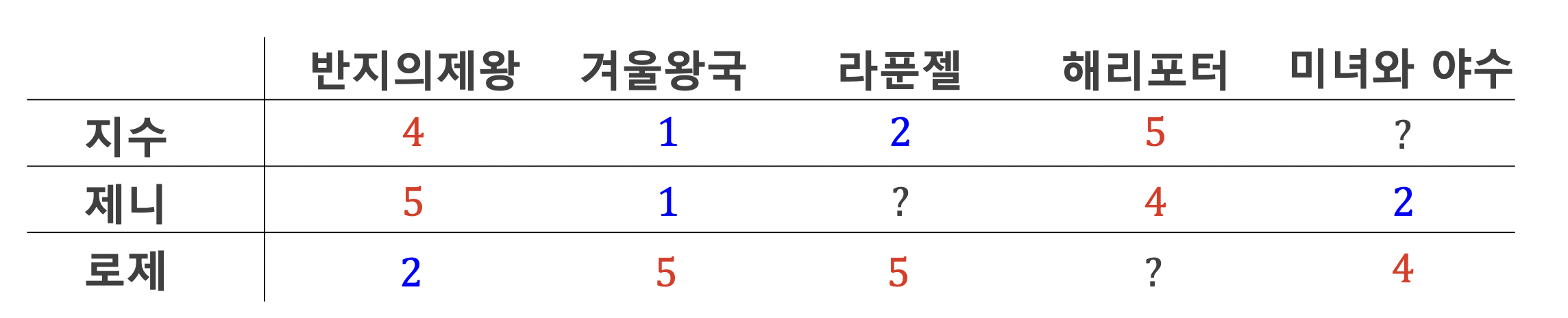
- 지수와 제니는 취향이 유사하고, 로제는 다른 취향을 가짐을 알 수 있음
- 피어슨 상관 계수 (Correlation Coefficient) 사용
-
상관 계수

- 두 사람이 한 상품에 대해 자신의 평균보다 높게 매기면 높아짐 (일치가 많아질 수록 양의값을 가짐)
- 각각 평균보다 높고 낮아지면 음의 값이 나옴 (불일치가 많아질 수록 음의값을 가짐)
- 분모는 정규화 목적

- 지수는 미녀와 야수를 좋아할 확률이 낮음, 비슷한 취향의 제니는 좋아하지 않고 다른 취향의 로제는 좋아했으므로
- 추천 과정
- 사용자 x 가 상품 s 에 대한 평가를 어떻게 할지, $r_\mathit{xs}$ 에 대해 추정
- 상품 s 를 구매한 사용자 중, x 와 취향이 가장 유사한 k 명의 사용자 N(x;s) 를 뽑아냄
- 아래 수식 사용
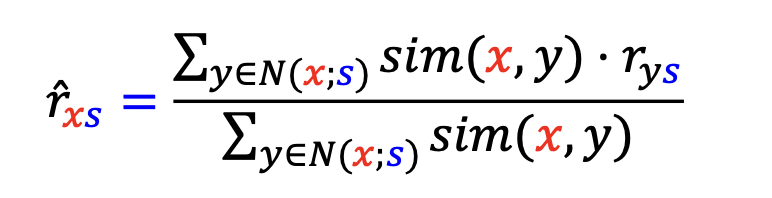
- x 가 구매하지 않은 여러 상품에 대해 위 과정을 진행하고 가장 추정 평점이 높은 상품을 추천
- 사용자 x 가 상품 s 에 대한 평가를 어떻게 할지, $r_\mathit{xs}$ 에 대해 추정
- 장점
- 상품에 대한 부가 정보가 없는 경우에도 사용 가능 (다른 사람의 평점 정보 필요)
- 단점
- 충분한 수의 평점 데이터가 누적되어야 효과적
- 새 상품, 새로운 사용자에 대한 추천 불가능
- 독특한 취향의 사용자에게 추천 힘듦
추천 시스템의 평가
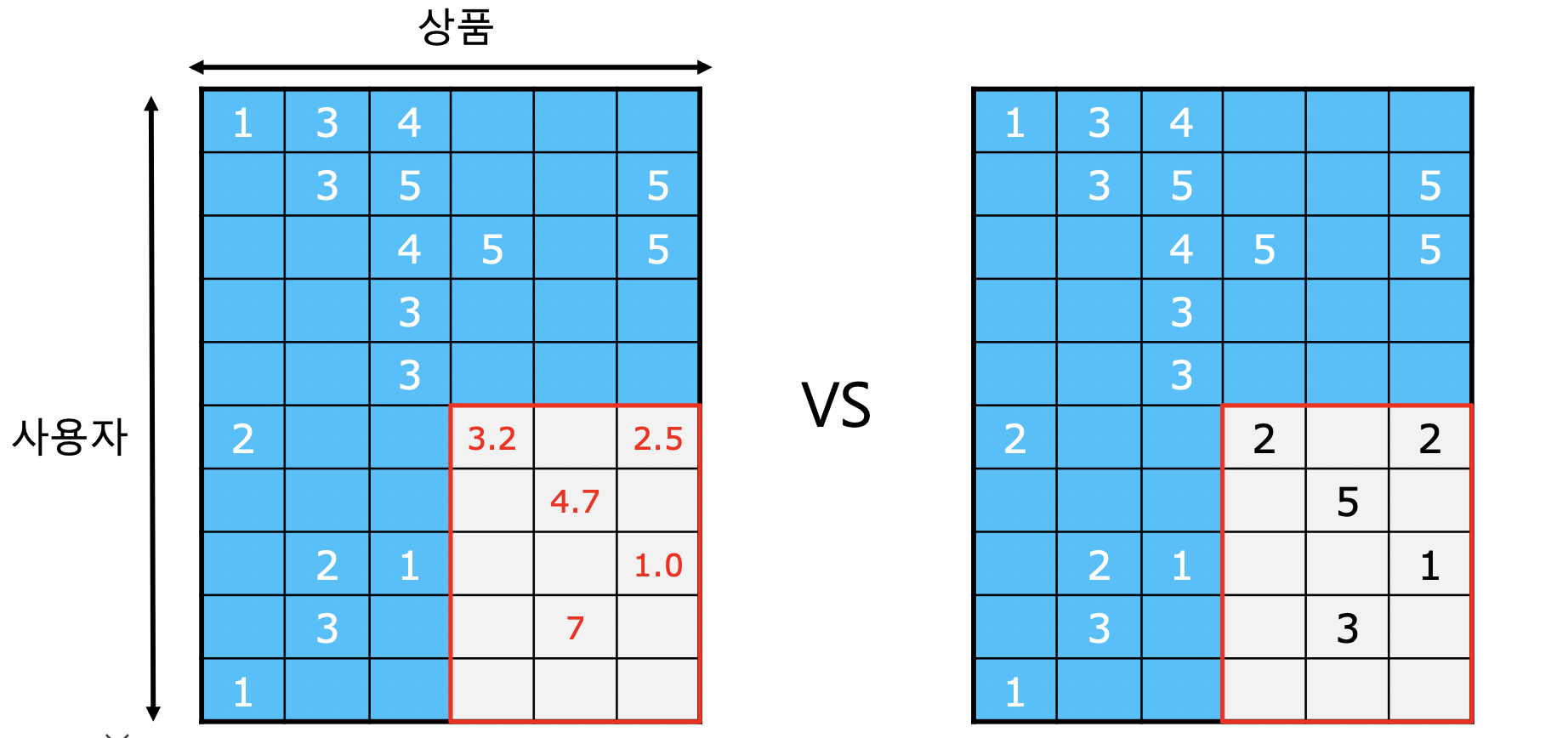
- 평점 데이터는 행렬로 표현 가능
- 훈련 데이터와 평가 데이터를 두고 평가 데이터의 평점을 추정함
- 추정 결과와 그라운드 트루스와 비교, loss 로 (MSE) 사용
- 이외에도 다양한 지표가 사용됨
- 추정 평점으로 순위를 매긴 후, 실제 평점의 순위와 상관 계수 계산
- 추천한 상품 중 실제 구매로 이루어진 것의 비율 측정
- 추천의 순서 혹은 다양성까지 고려하는 지표 사용
Further Reading
피어 세션
TED 세미나
MJ님이 GAN 에 관해 간략한 설명과 함께 GAN 을 이용해서 글씨체를 생성해주는 프로젝트를 설명해주셨다. GAN 에 대해 대충은 알고 있었지만 조금 더 자세히 알 수 있어서 좋았다. 특히 제너레이터에 들어가기 전 잠재벡터의 형태에 대해 확실히 알 수 있어서 좋았다.
Today I Felt
KEEP, Problem, Try
펭귄님의 부캠 회고록 포스팅을 보며 회고와 함께 앞으로 더 잘 헤쳐나가기 위해 KEEP, Problem, Try 를 해야겠다는 생각이 들었다. 지금처럼 매일 느낀 감정을 적는 것도 의미가 있지만 주차별로, 또는 정기적으로 잘 지켜나가고 있는 것과, 새로 닥친 문제점과 이를 극복할 방안을 생각해보고 실천하면 조금씩 더 좋은 습관과 노하우를 가진 엔지니어가 되지 않을까 생각한다 :)